
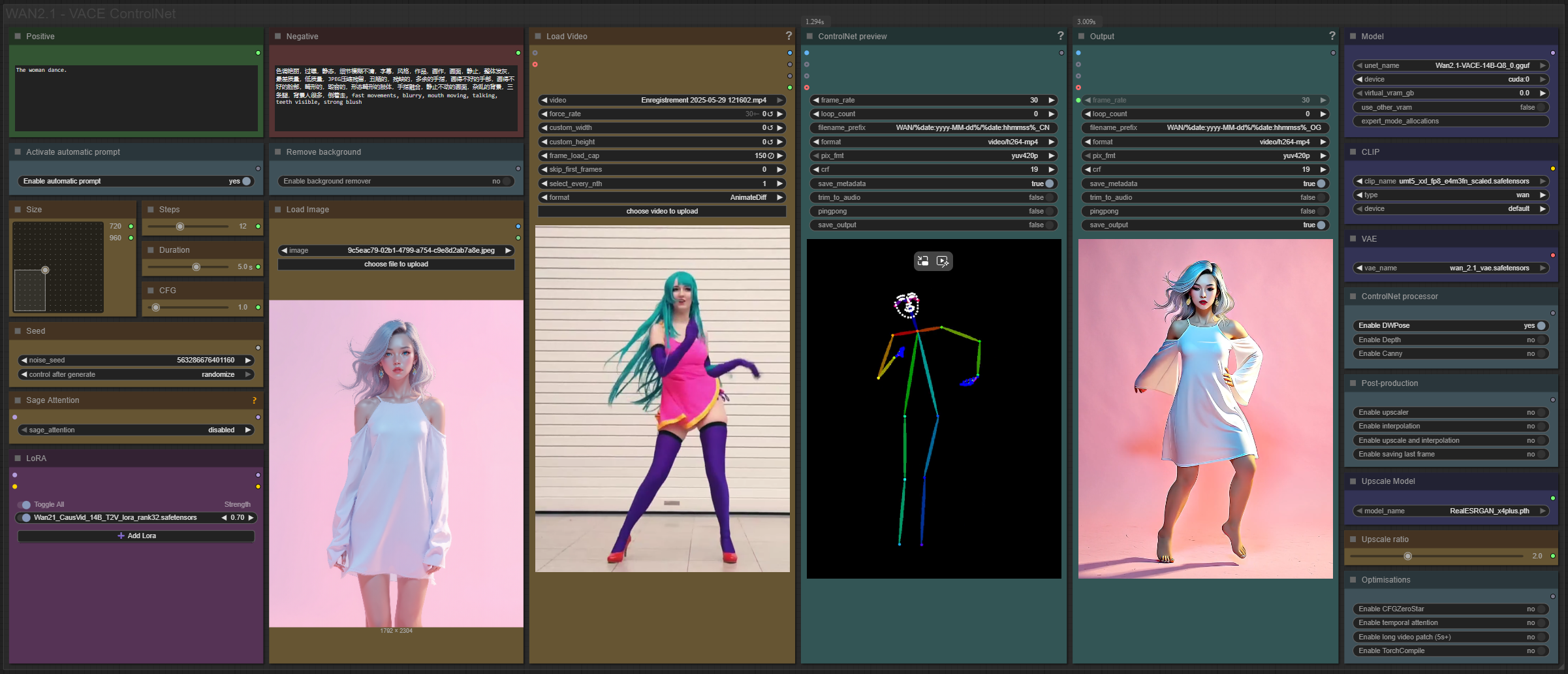
This workflow allows you to retrieve the movements of a video via controlnet (pose/canny or depth) and create a new video from an image of your choice with this movement.



Resources you need:
📂Files :
Recommendation :
>24 gb Vram: base or Q8_0
16 gb Vram: Q5_K_S
<12 gb Vram: Q4_K_S
For base version
VACE Model: wan2.1_vace_14B_fp8_e4m3fn.safetensors or wan2.1_vace_1.3B_fp16.safetensors
In models/diffusion_models
For GGUF version
VACE Quant Model: Wan2.1-VACE-14B-QX_0.gguf
In models/diffusion_models
CLIP: umt5_xxl_fp8_e4m3fn_scaled.safetensors
in models/clip
VAE: wan_2.1_vae.safetensors
in models/vae
LORA: Wan21_CausVid_14B_T2V_lora_rank32.safetensors
in models/lora
ANY upscale model:
Realistic : RealESRGAN_x4plus.pth
Anime : RealESRGAN_x4plus_anime_6B.pth
in models/upscale_models
📦Custom Nodes :

Description
base version
FAQ
Comments (42)
great workflow as always. Which gguf would work on 24gb vram? Also, does vace work with split sigmas?
I've done some testing and the split sigma isn't working at the moment. I've tried to publish a working version but I still have a lot of testing to do to optimize.
8GB VRAM + 32GB RAM possible with Q4?
This will be complicated but you should try by loading as much of the model as possible into RAM.
The legend returns! I can't wait to test this one out, thank you UmeAiRT!!
literally though i wrote this. but agreed
Excellent work! I am delighted with this workflow and the excellent images it helps produce. Thank you for your hard work!
I was waiting for this before I tried Vace. Works brilliantly and presented amazing as well. thanks!
Thank you very much. Can you give a good workflow for the recently released causvid and accvid acceleration lora? I have tried the ones released on the C site, but they are not easy to use. I look forward to your update.
In this workflow I added the lora causvid, does this method not seem easy to use?
@UmeAiRT Thanks, I'll try it
Hello @UmeAiRT I really love your workflow. Small question, did you tried something like in this one : https://civitai.com/models/1622023/causvid-2-sampler-workflow-for-wan-480p720p-i2v?modelVersionId=1835720
I read that causvid should have different values
unfortunately i'm not as expert as you in this domain
Maybe your could add such feature in your's different workflows
Everything ends on a StringConcatenate note, the control preview works and shows the result. Then nothing happens.
Failed to validate prompt for output 398:
* StringConcatenate 511:
- Failed to convert an input value to a INT value: frame_c, , invalid literal for int() with base 10: ' '
- Failed to convert an input value to a INT value: frame_b, , invalid literal for int() with base 10: ''
- Required input is missing: text_a
- Required input is missing: text_b
- Failed to convert an input value to a INT value: frame_a, , invalid literal for int() with base 10: ''
Output will be ignored
Failed to validate prompt for output 413:
Output will be ignored
Prompt executed in 0.41 seconds
I was having a similar problem with another one of Ume's (excellent) workflows and my workaround was to connect the positive prompt directly to the positive encode node. I think the problem is occurring when combining the Florence auto-prompt with the regular prompt. If you aren't using the auto-prompt anyways, connecting directly won't compromise anything else.
This bug is related to different versions of ComfyUI that have changed the "concatenate" node. You must have the latest version of ComfyUI for this to work in general or right-click on it and then "fix node"
Here is another error in the console:
File "F:\AI\ComfyUI_windows_portable\ComfyUI\comfy\ldm\wan\model.py", line 244, in forward
c = self.before_proj(c) + x
~~~~~~~~~~~~~~~~~~~~^~~
RuntimeError: The size of tensor a (46620) must match the size of tensor b (47880) at non-singleton dimension 1
An interesting fact is that it only works for me when setting the resolution to 480x480, but if you fix something on one parameter, the error I described above comes out.
Just to remember that clip too can be GGUF.
https://huggingface.co/city96/umt5-xxl-encoder-gguf/tree/main
Congratulations on your work, it's very good. I'm really enjoying it.
Thanks again for your work! However the output video keeps on being just a brown dense fog? what settings am I missing here?
(using DWPose and the controlnet video renders fine from my input video. it is "only" the actual output video that does not show)
now, the output is a yellow orange slow pace video of two womens faces!? Soo weird.. have tried all models and all apparent settings... doesnt change.
jay_rich i have a same thing
I also have the same problem
The dynamic range drops a lot. The black part collapses a lot. What should I touch? Thank you always
Excellent work!
Question: What setting can I change to keep a higher similiarity with the input iage and really to only get the movement from the video? The style changed too much for my taste. Thank you.
Have the same question. I ran with the default settings (CFG 1.0, combination of DWPose, Depth and Canny enabled) and kind of got something close to my input image, but it was still a different style than I intended. When I switched to just using DWPose, which is what I use in the other popular non-VACE WAN ControlNet workflow to some success, it turned my cartoony source image into a real person in the output video lol.
If we had control over the ControlNet strength for video like we do for images, then I feel like that would allow us to get closer to the source image.
It's been about a month since your comment though. Were you able to figure this out, either with this workflow or a different one?
So I just figured out that the CausVid_T2V lora the guide for this workflow suggests causes the realistic output I was getting. Without that, I get much closer to the original style but it could still be pushed much further.
I'm trying to mess with the strength value in the WanVaceToVideo node to see if that helps.
Always wanted to know what is better Base or GGUF version? What are the cardinal differences between them?
Going by my knowledge: gguf is compressed and loads slower and loses some quality. base is larger, faster in the sense that it doesn't need to be decompressed in runtime, however it requires more vram and takes also somewhat longer to load into vram because its bigger. gguf might be slightly worse in everything in direct comparison. For image gguf I remember how Q8 was basically almost default, Q5 first with slight quality loss, Q4 still acceptable. But for example on a 10gb vram gpu one had to use Q4 as it was the only model below 10gb size. In therms of workflow, the basic one has no gguf load workflow nodes included, therefore if you use gguf quants you need the gguf wf.
@lost_moon Thanks for the detailed answer! I couldn't understand because using both methods I get the same result in processing time.
String Concatenate broken
mxslider2d notes just look blank, if I do fix v2 they reappear for a second then disappear again. Anyone know how to fix this?
Hi! Please help me with this!!!!
KSampler
mat1 and mat2 shapes cannot be multiplied (154x768 and 4096x5120)
For me that's usually needing to use a different text encoder. Try changing the CLIP model used.
@arandomuser2839 Thanks!!
10/10
maybe it works well, but is not simple at all.
Simple is the name of my workflow series, advance thing like vace can look complex but you just have to import 1 image and 1 video and all is automatic
Really great workflow. How can I make the generated video keep the same style as my input image? I used the auto install script and left all the settings at default, but the output still changes a lot from the original image.
No matter the seetings it is either an OOM or a 'The size of tensor a (60840) must match the size of tensor b (62010) at non-singleton dimension 1' error
Maxed out virtual memory, on a 24GB VRAM card
Essentially with Q8 the workflow is using upwards of 50gb or memory through some magical reason.
Anyone else having this?
I had the same issue, but I could resolve the issue by using standard resolustion like 480p or 720p and it workd for me. (RTX 3090)
It worked for me. If you have encountered an issue like "'The size of tensor a (####) must match the size of tensor b (####) at non-singleton dimension 1" at Ksampler, that means your latent image size could be an issue.
Try to use standard resolution such as 480P or 720P. I used the exact model/Lora/Clip/Vae that the OP listed, and ran this workflow with RTX 3090 (Base Version).
Thank you for creating such a simple and easy workflow, OP!