

















Weekly MidJourney Style Experiment: Last 500 Images
Update (11/02/23) : adding WEEK 3 FFUsion (ALL IN) LoRA of Hot, Rising, and New
🗓 Current Week's Exploration (10.31.23): This week LoRAs are fine-tuned for the
🏆'Style Capture & Fusion Showdown' (rejected entry)
Week 3 Styles of Hot, Rising, and New MJ categories: 10.31.23

🔥 Previous Week’s LoRAs (10.23.23):
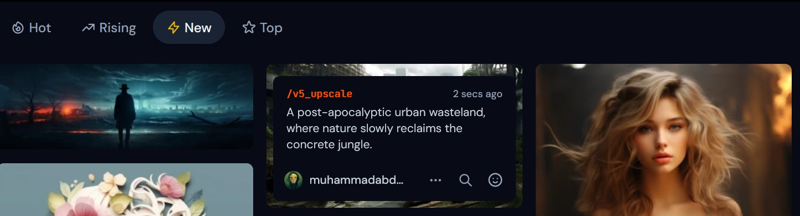
last week styles from the 'Hot', 'Rising', and 'New' category



A recent experiment conducted using the last 500 images from the 'MidJourney' categories: Hot, Rising, and New.



Data Acquisition and Integrity:
All images were sourced responsibly, with no use of unofficial tools for acquisition.
The images were obtained using the sanctioned Corporate/Enterprise account.
Technical Overview:
The images were processed using the
ViT-L-14/openaimodel (quick sloppy run). For testing, theprodigytool was employed.It's important to note that the current quality of results does not align with our typical production standards. However, for those interested in further details, a training set from the official Civitai trainer is available.
The experiment utilized the capabilities of the Civitai trainer(default out of the box configuration)
09/26/2023 03:48:12 AM
SUBMITTED
09/26/2023 03:48:40 AM
PROCESSING
09/26/2023 05:21:46 AM
READY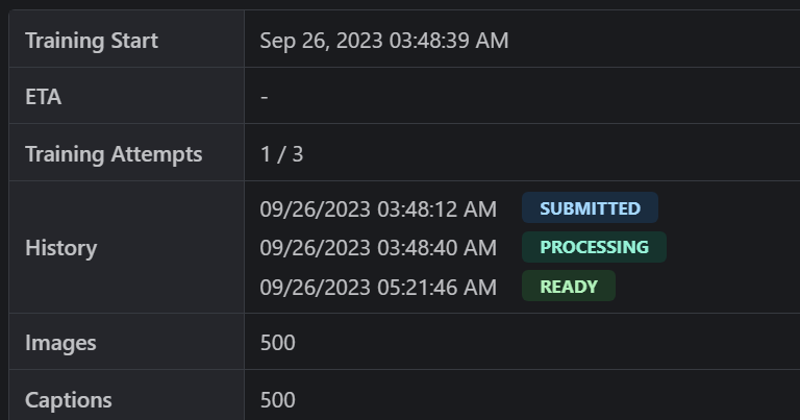
Lora FA text encoder, and the Kohya tools, all operating on the H100 80GB.
We appreciate your continued interest and support. Further updates will be provided as the experiment progresses.
Each one took 20-30min 
📂 MidJ_Last_500_-_Experiment.safetensors
📅 Date:
2023-09-26T02:20:38🏷️ Title:
MidJ_Last_500_-_Experiment🖼️ Resolution:
1024x1024🧪 Architecture:
stable-diffusion-xl-v1-base/lora🌐 Network Dimensions:
Dim/Rank:
32.0Alpha:
16.0
🔌 Module:
networks.lora🔧 Configurations:
Learning Rate:
0.0005UNet LR:
0.0005TE LR:
5e-05Optimizer:
bitsandbytes.optim.adamw.AdamW8bit(weight_decay=0.1)Scheduler:
cosine_with_restartsWarmup Steps:
0Epochs:
10Batches per Epoch:
128Gradient Accumulation Steps:
1Train Images:
500Regularization Images:
0Multires Noise Iterations:
6.0Multires Noise Discount:
0.3Min SNR Gamma:
5.0Zero Terminal SNR:
TrueMax Gradient Norm:
1.0Clip Skip:
1Dataset Directories:
1Image Count:
500 images
📈 Stats:
UNet Weight (Avg. Magnitude):
3.0170UNet Weight (Avg. Strength):
0.0111Text Encoder (1) - Weight (Avg. Magnitude):
1.7304Text Encoder (1) - Weight (Avg. Strength):
0.0087Text Encoder (2) - Weight (Avg. Magnitude):
1.7614Text Encoder (2) - Weight (Avg. Strength):
0.0068
📂 FF-Midj-Last-v0563.safetensors
📅 Date:
2023-09-26T01:16:09🏷️ Title:
FF-Midj-Last-v0563🖼️ Resolution:
1024x1024🧪 Architecture:
stable-diffusion-xl-v1-base/lora🌐 Network Dimensions:
Dim/Rank:
64.0Alpha:
32.0
🔌 Module:
networks.lora📈 Stats:
UNet Weight (Avg. Magnitude):
2.6731UNet Weight (Avg. Strength):
0.0076Text Encoder (1) - Weight (Avg. Magnitude):
2.5809Text Encoder (1) - Weight (Avg. Strength):
0.0091Text Encoder (2) - Weight (Avg. Magnitude):
2.6613Text Encoder (2) - Weight (Avg. Strength):
0.0072
📂 FF-Midj-Rise-v0564.safetensors
📅 Date:
2023-09-26T02:01:20🏷️ Title:
FF-Midj-Rise-v0564🖼️ Resolution:
1024x1024🧪 Architecture:
stable-diffusion-xl-v1-base/lora🌐 Network Dimensions:
Dim/Rank:
64.0Alpha:
32.0
🔌 Module:
networks.lora📈 Stats:
UNet Weight (Avg. Magnitude):
2.6016UNet Weight (Avg. Strength):
0.0074Text Encoder (1) - Weight (Avg. Magnitude):
2.5694Text Encoder (1) - Weight (Avg. Strength):
0.0091Text Encoder (2) - Weight (Avg. Magnitude):
2.6260Text Encoder (2) - Weight (Avg. Strength):
0.0071
📂 FF-Midj-Top-v0564-FA-TX.safetensors
📅 Date:
2023-09-26T03:21:49🏷️ Title:
FF-Midj-Top-v0564-FA-TX🖼️ Resolution:
1024x1024🧪 Architecture:
stable-diffusion-xl-v1-base/lora🌐 Network Dimensions:
Dim/Rank:
64.0Alpha:
64.0
🔌 Module:
networks.lora_fa📈 Stats:
Text Encoder (1) - Weight (Avg. Magnitude):
5.8341Text Encoder (1) - Weight (Avg. Strength):
0.0191Text Encoder (2) - Weight (Avg. Magnitude):
6.0269Text Encoder (2) - Weight (Avg. Strength):
0.0153
⚠️ Note: No UNet found in this LoRA.
🌐 FFusion.ai Contact Information
Proudly maintained by Source Code Bulgaria Ltd & Black Swan Technologies.
📧 Email Us: [email protected] - For inquiries or support.
🌍 Locations: Sofia | Istanbul | London
Connect with Us:
Our Websites:
Description
📂 FF-Midj-Rise-v0564.safetensors
📅 Date:
2023-09-26T02:01:20🏷️ Title:
FF-Midj-Rise-v0564🖼️ Resolution:
1024x1024🧪 Architecture:
stable-diffusion-xl-v1-base/lora🌐 Network Dimensions:
Dim/Rank:
64.0Alpha:
32.0
🔌 Module:
networks.lora📈 Stats:
UNet Weight (Avg. Magnitude):
2.6016UNet Weight (Avg. Strength):
0.0074Text Encoder (1) - Weight (Avg. Magnitude):
2.5694Text Encoder (1) - Weight (Avg. Strength):
0.0091Text Encoder (2) - Weight (Avg. Magnitude):
2.6260Text Encoder (2) - Weight (Avg. Strength):
0.0071
FAQ
Comments (6)
cool
Were these trained with text encoder containing similar keywords used in the prompts in MJ?
processed using ViT-L-14/openai and subsequently, the text encoder was trained on "LoRA-FA" network utilizing the Kohya tools on an 80GB H100 platform. It's worth noting that the original prompts were intentionally excluded in this version. However, for next week's batch, I can prepare separate versions of the encoder using both sets of prompts to evaluate the differences.
PS: do try mixing the encoder LoRA-FA with the others for unexpected results :D
"<lora:FF-Midj-Top-v0564-FA-TX:1> <lora:FF-Midj-Top-v0565:0.29> <lora:FF-Midj-Rise-v0564:0.1> <lora:FF-Midj-Last-v0563:0.11> <lora:MidJ_Last_500_-_Experiment:0.21> "
@idle Can you explain a bit more about mixing the encoder LoRA-FA? I'm using ComfyUI.... so I don't know how to do that there.
@EricRollei21 you can use multiple lora loaders just feed the model and clip noodles into each lora and then into the additional loras, you can load all 5 of his loras if you want and daisy chain them. Just feed the clip and model from the last lora in the chain into the clip text, sampler and vae. oh well didn't notice this was a month old.
@zathoros Thanks, I thought it was something special - Comfyui has some interesting merge model mixers that can mix models on gen