
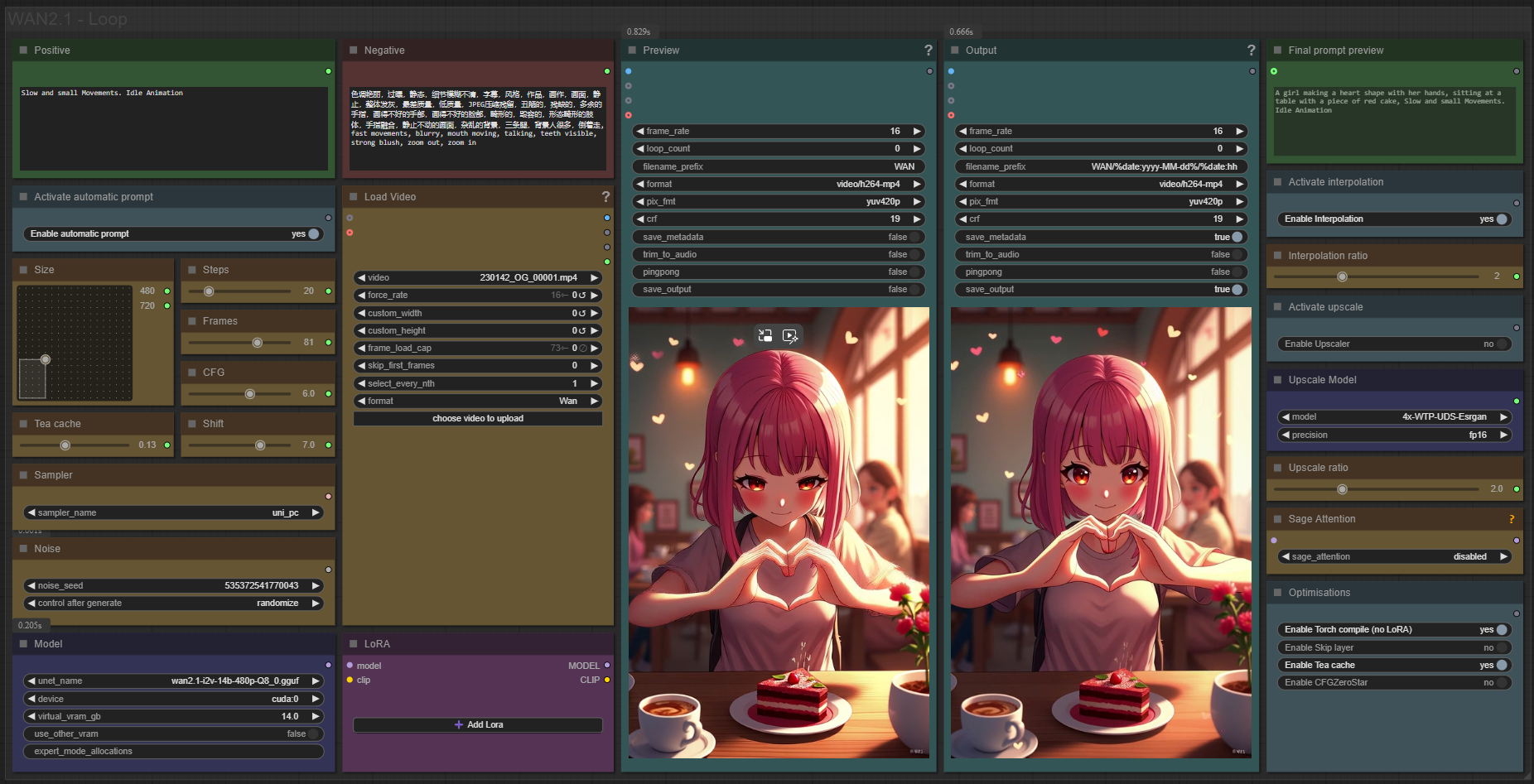
This workflow uses Wan2.1 VACE to turn any input video into a seamless loop.
It feeds the last 15 frames of the input video, a X-30 frame blank segment, and the first 15 frames into VACE to generate a transition.
Finally, it removes the overlapping 30 frames (15 from the end and 15 from the start) and merges the result with the original video for output.



Resources you need:
📂Files :
Recommendation :
>24 gb Vram: base or Q8_0
16 gb Vram: Q5_K_S
<12 gb Vram: Q4_K_S
For base version
VACE Model: wan2.1_vace_14B_fp8_e4m3fn.safetensors or wan2.1_vace_1.3B_fp16.safetensors
In models/diffusion_models
CLIP: umt5_xxl_fp8_e4m3fn_scaled.safetensors
in models/clip
For GGUF version
VACE Quant Model: Wan2.1-VACE-14B-QX_0.gguf
In models/diffusion_models
Quant CLIP: umt5-xxl-encoder-QX.gguf
in models/clip
VAE: wan_2.1_vae.safetensors
in models/vae
ANY upscale model:
Realistic : RealESRGAN_x4plus.pth
Anime : RealESRGAN_x4plus_anime_6B.pth
in models/upscale_models
📦Custom Nodes :

Description
What's new? :
ComfyUi 0.3.29 positive node fix,
Fix color aberation for last frame,
LoRA fix with torch compile.
FAQ
Comments (5)
Having a hard time understanding this use for this one Start Frame End Frame exists?
When I import this with all the custom nodes installed correctly, most of the nodes are missing links? Attempting to run the workflow gives me a wall of errors due to missing inputs on many nodes.
https://i.imgur.com/5FUDWaf.png
{kind=link}
I have the same issue with your Start/End frame workflow... but your base workflow for I2V worked fine for me all this time 🤔
is it possible to make a variant with the new vace technology?
Heya!
I just can't seem to get the workflow to run through completely :/
at around 80% of the tensorrt upscaling i always get an inference failed error because of an out of memory issue.
The first thing i notice is that the "Remove lastframe"-Node is disabled inside the "Merge video"-Group by default, but if it's disabled the getfirstFrame-Node in the same Group does not have a default value for it's length resulting in the output extention and therefore the upscaling to never happen. It just ends before merging.
I have a 4090 and i'm using the exact same settings in the normal IMG2Video workflow that i'm using in the Loop workflow. The IMG2Video workflow works flawlessly even at 3x or 4x upscaling. But in the Loop workflow even an upscaling of 2x results in the following problems.
This is my error log:
[ComfyUI-Upscaler-Tensorrt|INFO] - Loading TensorRT engine: G:\pinokio\api\comfy.git\app\models\tensorrt\upscaler\4x_foolhardy_Remacri_fp16_1x3x256x256_1x3x512x512_1x3x1280x1280_10.9.0.34.trt [ComfyUI-Upscaler-Tensorrt|INFO] - Upscaling 441 images from H:768, W:512 to H:3072, W:2048 | Final resolution: H:3072, W:2048 | resize_to: none [W] 'colored' module is not installed, will not use colors when logging. To enable colors, please install the 'colored' module: python3 -m pip install colored [E] IExecutionContext::enqueueV3: Error Code 1: Cuda Driver (out of memory) !!! Exception during processing !!! ERROR: inference failed. Traceback (most recent call last): File "G:\pinokio\api\comfy.git\app\execution.py", line 347, in execute output_data, output_ui, has_subgraph = get_output_data(obj, input_data_all, execution_block_cb=execution_block_cb, pre_execute_cb=pre_execute_cb) File "G:\pinokio\api\comfy.git\app\execution.py", line 222, in get_output_data return_values = _map_node_over_list(obj, input_data_all, obj.FUNCTION, allow_interrupt=True, execution_block_cb=execution_block_cb, pre_execute_cb=pre_execute_cb) File "G:\pinokio\api\comfy.git\app\custom_nodes\comfyui-lora-manager\py\metadata_collector\metadata_hook.py", line 63, in map_node_over_list_with_metadata results = original_map_node_over_list(obj, input_data_all, func, allow_interrupt, execution_block_cb, pre_execute_cb) File "G:\pinokio\api\comfy.git\app\custom_nodes\comfyui-lora-manager\py\metadata_collector\metadata_hook.py", line 63, in map_node_over_list_with_metadata results = original_map_node_over_list(obj, input_data_all, func, allow_interrupt, execution_block_cb, pre_execute_cb) File "G:\pinokio\api\comfy.git\app\execution.py", line 194, in _map_node_over_list process_inputs(input_dict, i) File "G:\pinokio\api\comfy.git\app\execution.py", line 183, in process_inputs results.append(getattr(obj, func)(**inputs)) File "G:\pinokio\api\comfy.git\app\custom_nodes\ComfyUI-Upscaler-Tensorrt\__init__.py", line 62, in upscaler_tensorrt result = upscaler_trt_model.infer({"input": img}, cudaStream) File "G:\pinokio\api\comfy.git\app\custom_nodes\ComfyUI-Upscaler-Tensorrt\trt_utilities.py", line 265, in infer raise ValueError("ERROR: inference failed.") ValueError: ERROR: inference failed. Prompt executed in 227.07 seconds Error handling request Traceback (most recent call last): File "G:\pinokio\api\comfy.git\app\env\lib\site-packages\aiohttp\web_protocol.py", line 480, in _handle_request resp = await request_handler(request) File "G:\pinokio\api\comfy.git\app\env\lib\site-packages\aiohttp\web_app.py", line 569, in _handle return await handler(request) File "G:\pinokio\api\comfy.git\app\env\lib\site-packages\aiohttp\web_middlewares.py", line 117, in impl return await handler(request) File "G:\pinokio\api\comfy.git\app\server.py", line 50, in cache_control response: web.Response = await handler(request) File "G:\pinokio\api\comfy.git\app\server.py", line 142, in origin_only_middleware response = await handler(request) File "G:\pinokio\api\comfy.git\app\server.py", line 523, in system_stats vram_total, torch_vram_total = comfy.model_management.get_total_memory(device, torch_total_too=True) File "G:\pinokio\api\comfy.git\app\comfy\model_management.py", line 206, in get_total_memory _, mem_total_cuda = torch.cuda.mem_get_info(dev) File "G:\pinokio\api\comfy.git\app\env\lib\site-packages\torch\cuda\memory.py", line 712, in mem_get_info return torch.cuda.cudart().cudaMemGetInfo(device) RuntimeError: CUDA error: out of memory CUDA kernel errors might be asynchronously reported at some other API call, so the stacktrace below might be incorrect. For debugging consider passing CUDA_LAUNCH_BLOCKING=1 Compile with `TORCH_USE_CUDA_DSA` to enable device-side assertions.What surprises me is that it says it's trying to upscale the images from 512x768 to 2048x3072, so it's trying to upscale 4x even though i have set the upscaling to "only" 2.0.
It happens with both the 480p and the 720p model.
This is the workflow with my values, do you see anything that might look out of the ordinary?
https://www.mediafire.com/file/mmb4qb8mowkdmix/WAN2.1_-_VIDEO_to_LOOP_%2528gguf%2529.json/file