










*Important, please read this before using the model because this is very experimental, I think the training direction is right but it will struggle with hand and complex pose at the moment.
You can download the clip text encoder here: https://huggingface.co/suzushi/miso-diffusion-m-1.1
Though I merged the clip encoder as well so you can use it directly (without t5).
You can use it like this in comfy ui if you prefer to use t5 :
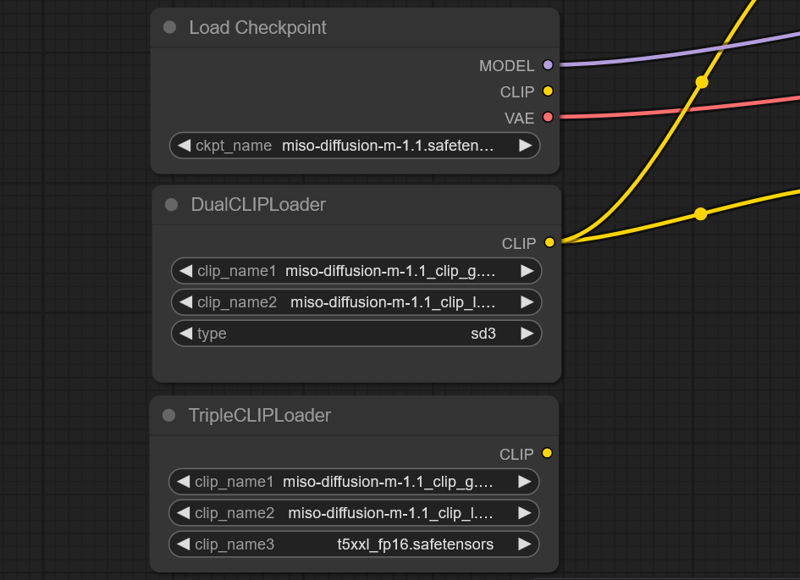
This version is trained with 710k image for 5 epoch.
Roughly 261 hours, running a epoch cost around 80 dollars, training a base model is costly, so if possible please consider supporting this project, the cost to develop SD3.5 medium model is slightly lower then sdxl, thousand dollar would allow me to train a million image class model for 10 epoch: https://ko-fi.com/suzushi2024, if there's any money left it will go towards lora training in the future.
Development roadmap:
The larger dataset is still in processing, 2.0 aims to be utilize 1.2-1.5 million image dataset and 3.0 aimed at 2.5 million.
Opensource commitment:
This is a little tool I used to prepare my dataset: https://github.com/suzushi-tw/wd14-toolkit
Roughly 570 dollars was spend on processing the danbooru dataset, each tar file comes with image pair with its txt file as well as characters_list, feel free to use the dataset:
https://huggingface.co/suzushi
Recommanded setting, euler, cfg:5 , 32-36 steps, (denoise: 0.95 or 1 )
prompt: danbooru style tagging. I recommand simply generating with a batch size of 4 to 8 and pick the best one.
Quality tag
Masterpiece, Perfect Quality, High quality, Normal Quality, Low qualityAesthetic Tag
Very Aesthetic, aestheticPleasent
Very pleasent, pleasent, unpleasentAdditional tag: high resolution, elegant
Slight increase in learning rate, the model is far from finished,
every epoch still shows significant improvement.
Training setting: Adafactor with a batchsize of 40, lr_scheduler: cosine
SD3.5 Specific setting:
enable_scaled_pos_embed = true
pos_emb_random_crop_rate = 0.2
weighting_scheme = "flow"
learning_rate = 3.5e-6
learning_rate_te1 = 2.5e-6
learning_rate_te2 = 2.5e-6
Train Clip: true, Train t5xxl: false