KXSR First-Person Flight Concept LorA for WAN 2.1 14B and 1.3B T2V
In collaboration with @machinedelusions [https://civarchive.com/user/machinedelusions]
KXSR Labs presents:
This LoRA enables the creation of cinematic first-person perspective flying. The hands can be customized in the prompt provided or omitted from the prompt for raw forward camera movement. The typical view will be from a first-person perspective with dynamic movement in horizontal aspect ratio generation. Can still create fun results at other aspect ratios/resolutions.
Use the trigger word "kxsr" to activate the model's specialized training.
Prompt Format
kxsr, [flying in first-person perspective/a person flying in first-person perspective] [broad description of landscape] [describe visible body parts (hands/fists)] [describe movement direction and speed] [describe additional environmental details encountered during flight]
Example Prompts
kxsr, a person flying in first-person perspective through a raging forest fire, the camera descends through burning trees with smoke and ash rising into the sky
=================================================
kxsr, a person flying in first-person perspective through an underwater atlantis city, mermaid hands with painted fingernails visible, the camera descends into bubbling water and zooms through the sunken ornate ruinsRecommended Settings
CFG: 4
Shift value: 4.0
LoRA strength: 1.0
~73 frames
720x1280 horizontal aspect ratio
Technical Details
Base model: WAN 2.1 14B and 1.3B Text2Video
Training dataset: 62 clips
Resolution: 1280 x 720 (horizontal format)
Frame count: 73 frames per clip
For optimal results, maintain these specifications during inference
This LoRA works best when you provide detailed descriptions of both the subject and the surrounding environment while following the prescribed format.
Screenshot shows my typical inference testing setup for lora evals: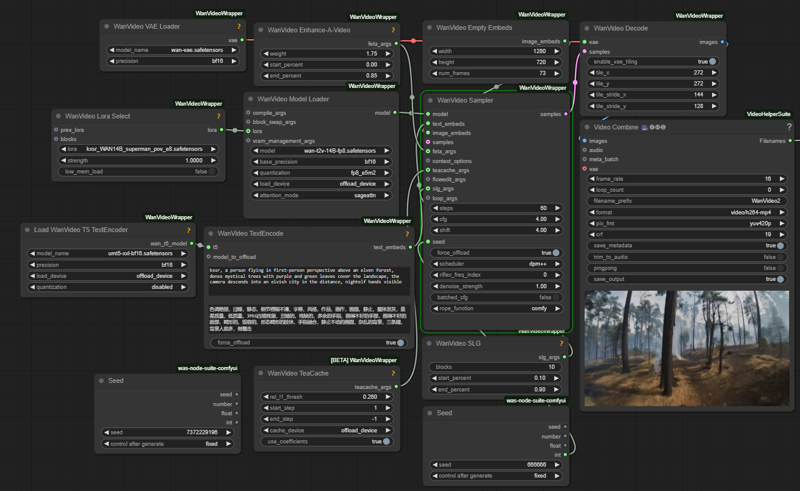
Description
FAQ
Comments (7)
Do t2v Loras also work with i2v?
yes! so long as you use the 14B T2V loras since I2V is only on the 14B parameter models
👍🏻👍🏻👍🏻
Curious... what types of training clips are involved in making this LoRA?
Like how much variety and how many samples?
Does the accompanying text has to capture the full detail of a scene or just the important concept like "x flying from y pov"?
I cut up the video https://www.youtube.com/watch?v=H0Ib9SwC7EI from Corridor Digital that they posted 11 years ago! I took several of the best moments from this video and clipped them out each 3 seconds long. I captioned it almost exactly as I show the prompt structure here in the model description.
@Kytra Damn.... that is interesting how you could get away with only one video/ style, and extrapolate the concept to varying scenes. I was thinking you must have used a variety of clips with different artistic styles like cartoons, sci-fi/fantasy movies, video games, etc...
Great work!
@aungkhant0911 Thank you! Yeah WAN is incredibly capable model. I made sure that my captions always described the environment in great detail so the model would not associate KXSR as a token with any particular environment and instead it would explicitly learn the camera movement and altitude.
Details
Files
Available On (2 platforms)
Same model published on other platforms. May have additional downloads or version variants.