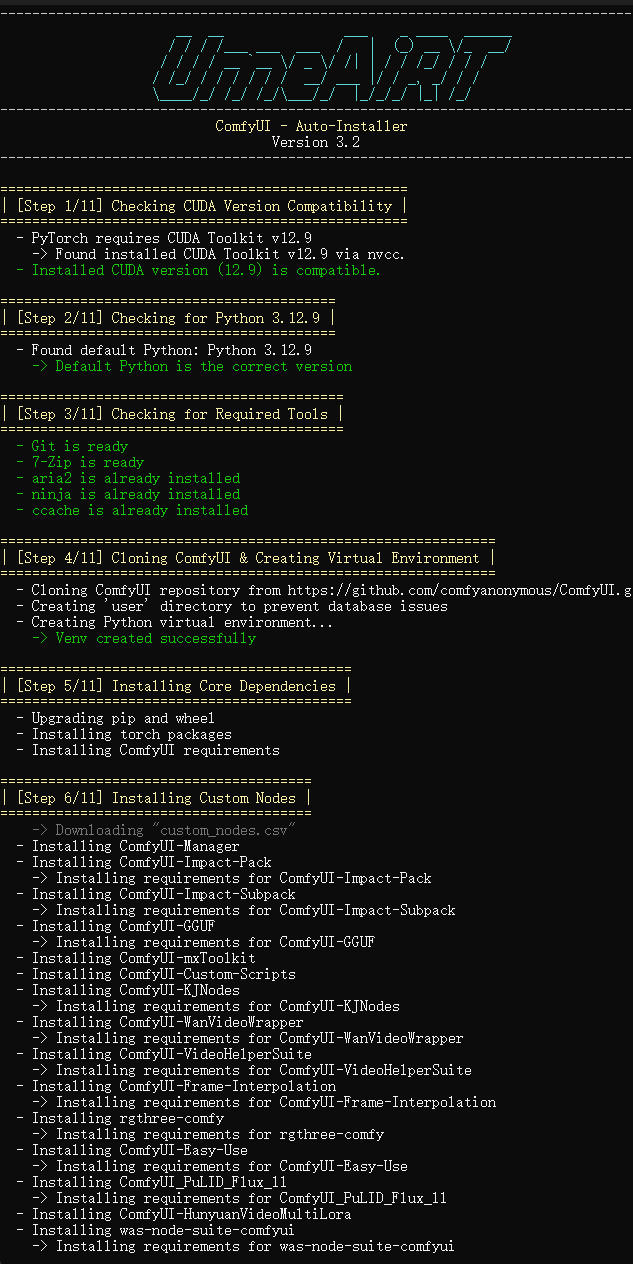
🚀 ComfyUI Auto-Installer — v5 (Python Rewrite)
Version 5 is a full rewrite from the ground up in Python, replacing all the PowerShell scripts from previous versions. It's cross-platform, faster, smarter, and now ships with a TUI manager, Docker images, and GPU-optimized inference out of the box.
If you are upgrading from the PowerShell version (v4.x), a one-command migration preserves all your models, outputs, and custom nodes: irm https://get.umeai.art/migrate.ps1 | iex
⚡ Quick Start (One-Liner)
Windows (PowerShell):
irm https://get.umeai.art/comfyui.ps1 | iexLinux / macOS:
curl -fsSL https://get.umeai.art/comfyui.sh | sh
Only requires Git — everything else (Python, uv, dependencies) is handled automatically.
✨ What's New in v5
Full Python rewrite — no more PowerShell dependency
Cross-platform — Windows, Linux, macOS, and Docker
TUI Manager — interactive terminal UI to launch, update, download models, and configure settings
VRAM-aware model catalog — 7 model families with quantization recommendations based on your GPU
GPU auto-detection — NVIDIA (CUDA 13.0/12.8), AMD (ROCm/DirectML), Apple Silicon (MPS)
SageAttention 2 + 3 — pre-compiled wheels including RTX 50XX Blackwell support
One-click update — update ComfyUI, all nodes, and dependencies with a single command
Model security scanner — detects malicious pickle code in .ckpt/.pt files
Junction architecture — models and outputs persist independently from ComfyUI updates
Docker ready — 4 image variants including a cloud version with JupyterLab for RunPod
📋 Prerequisites
Git
GPU: NVIDIA (CUDA 12.x+), AMD (Radeon RX 6000+), or Apple Silicon (M1+)
Internet connection
Note: Python is automatically installed via uv if not present. No manual Python setup required.
🎨 Model Catalog (7 Families)
Interactive model downloader with VRAM-based recommendations (★ markers) and SHA-256 integrity checks. Each bundle offers multiple quantization variants (fp16, fp8, GGUF Q3→Q8). Downloads are accelerated via aria2c with HuggingFace + ModelScope fallback:
FLUX (Image): Dev, Fill
Z-IMAGE (Image): Turbo
WAN 2.1 (Video): T2V, I2V 480p
WAN 2.2 (Video): I2V, Fun Inpaint, Fun Camera
HiDream (Image): Dev
QWEN (Image Edit): Image Edit
LTX-2 (Video + Audio): Dev
🧩 34 Custom Nodes Included
Additive manifest — never removes user-installed nodes.
Core (always installed): ComfyUI-Manager
UmeAiRT Tier: ComfyUI-UmeAiRT-Sync, ComfyUI-UmeAiRT-Toolkit, ComfyUI-Crystools, ComfyUI-nunchaku
Full Tier (all of the above +): ComfyUI-Impact-Pack, ComfyUI-Impact-Subpack, ComfyUI-GGUF, ComfyUI-mxToolkit, ComfyUI-Custom-Scripts, ComfyUI-KJNodes, ComfyUI-WanVideoWrapper, ComfyUI-VideoHelperSuite, ComfyUI-Frame-Interpolation, rgthree-comfy, ComfyUI-Easy-Use, ComfyUI-HunyuanVideoMultiLora, ComfyUI-Florence2, ComfyUI-MultiGPU, ComfyUI-WanStartEndFramesNative, ComfyUI-Image-Saver, ComfyUI_UltimateSDUpscale, comfyui_controlnet_aux, x-flux-comfyui, ComfyUI-Detail-Daemon, wlsh_nodes, ComfyUI_essentials, ComfyUI-wanBlockswap, Derfuu_ComfyUI_ModdedNodes, ComfyUI_LayerStyle, ComfyUI-Upscaler-Tensorrt, comfyui-vrgamedevgirl, comfyui-int-and-float, was-node-suite-comfyui
⚙️ GPU Optimizations (Auto-Installed)
PyTorch 2.10: CUDA 13.0/12.8, ROCm 7.1, DirectML, MPS
xformers: Memory-efficient attention
Triton: triton-windows / triton (Linux)
SageAttention 2: Unified ABI3 wheels (Windows), per-arch SM80–SM100 (Linux)
SageAttention 3: RTX 50XX Blackwell native (Windows + Linux)
FlashAttention: Linux + NVIDIA only
Nunchaku & InsightFace: Pre-compiled wheels
Additional Python packages auto-installed: facexlib, onnxruntime-gpu, nvidia-ml-py, cupy-cuda13x, imageio-ffmpeg, hf_xet, cython, rotary_embedding_torch, blend_modes, segment_anything, gguf, and more.
🐳 Docker Support
Requires Docker and an NVIDIA GPU: docker run --gpus all -p 8188:8188 -v comfyui-data:/data registry.gitlab.com/umeairt-studio/comfyui-auto_installer-python:latest
latest: ~4 GB — Ready to go with pre-installed PyTorch
latest-cloud: ~4.5 GB — + JupyterLab for RunPod / cloud
latest-lite: ~2 GB — Minimal (installs PyTorch on first run)
latest-lite-cloud: ~2 GB — Lite + JupyterLab
🔒 Security
No external script execution — all logic is internalized
Secure subprocess calls — no shell=True
HTTPS only — all URLs validated
SHA-256 integrity checks on all model downloads
Pickle model scanner — detects malicious code in .ckpt/.pt files
Zip-slip prevention on archive extraction
CI runs Bandit + pip-audit on every push
📂 Post-Installation
Three launcher scripts are generated:
UmeAiRT-Start-ComfyUI: Launch (Performance mode + SageAttention)
UmeAiRT-Start-ComfyUI_LowVRAM: Launch with --lowvram --fp8 for ≤8 GB VRAM
UmeAiRT-Manager: TUI manager (update, download, reinstall, settings)
🔗 Links
Source code: GitLab (https://gitlab.com/UmeAiRT-Studio/ComfyUI-Auto_installer-Python)
Mirror: Codeberg (https://codeberg.org/UmeAiRT)
Ecosystem: UmeAiRT Studio (https://umeai.art)
Description
Add WAN2.2,
Add QWEN,
New code structure.
FAQ
Comments (38)
Thank you for all the hard work, this works like a charm! THANK YOU!
This worked great, thank you. When i tried to update I got this error:
Invoke-WebRequest : The request was aborted: The connection was closed unexpectedly.
At line:1 char:82
+ ... pe]::Tls12; Invoke-WebRequest -Uri 'https://github.com/UmeAiRT/ComfyU ...
+ ~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
+ CategoryInfo : InvalidOperation: (System.Net.HttpWebRequest:HttpWebRequest) [Invoke-WebRequest], WebExc
eption
+ FullyQualifiedErrorId : WebCmdletWebResponseException,Microsoft.PowerShell.Commands.InvokeWebRequestCommand
- Download of Download-HIDREAM-Models.ps1...
- Download of Download-LTXV-Models.ps1...
[OK] Updated scripts.
[INFO] Launching the main installation script...
FATAL: dependencies.json not found...
Yeah, past few versions of this install, the update script doesn't work, breaks with that error. Made the mistake of installing impact subpack to get ultralytics and like so much of the dev for comfy, the authors are often no better than feral cats and go and unistall things like numpy and screw up some other node, in this case nunchaku. Last time it was WAS. Looks like it's re-install Comfy, again.
I even did a checkpoint before installing the new node, because I KNEW this was what was going to happen but half the time the manager doesn't do anything useful, or correct, or well. Not this fellow's fault, ComfyUI is not a stable platform, is a complete mess of a design on the back end. Just imagine if you weren't running it in a virtual environment what these random node authors might do if they just willy-nilly decided to install and unistall system level stuff. It's inexcusable that the Comfy authors let one node mess with another.
pocketsVFX well thanks to your installer I finally got torch and sage working, so than you! Looking forward to the next package.
To facilitate the addition of future models, and improve the update process, I had to greatly change the code, which broke the old version of the script.
AbsoluteReality oh, not my installer, it's this guy but I think I know what you mean. I'm very thankful for his work because now I know you basically have to be ready on the daily to re-install ComfyUI, again, with any individual node addition. I'd rather just do that and copy my models and lora and workflows folder over to a new install than monkey with chatgpt to untangle yet a new mess.
1)
wan2.2_t2v_high_low_14B_fp8_scaled.safetensors
wan2.2_i2v_high_low_14B_fp8_scaled.safetensors
takes a lot of time to download these two models, but at the end, they're nowhere to be seen.
I assume this is the reason for the problem (Download-WAN2.2-Models.ps1):
Download-File -Uri "$baseUrl/diffusion_models/WAN/wan2.2_i2v_high_low_14B_fp8_scaled.safetensors" -OutFile (Join-Path $wanDiffDir "wan2.2_i2v_low_noise_14B_fp8_scaled.safetensors")
Download-File -Uri "$baseUrl/diffusion_models/WAN/wan2.2_t2v_high_low_14B_fp8_scaled.safetensors" -OutFile (Join-Path $wanDiffDir "wan2.2_t2v_low_noise_14B_fp8_scaled.safetensors")
2)
QWEN models are not downloaded.
immediately skips to "QWEN model downloads complete."
Do you want to download QWEN base models?
A) bf16
B) fp8
C) All
D) No
Enter your choice and press Enter: b
Do you want to download QWEN GGUF models?
A) Q8_0
B) Q5_K_S
C) Q4_K_S
D) All
E) No
Enter your choice and press Enter: e
Starting QWEN model downloads...
Downloading QWEN base model...
QWEN model downloads complete.
Press Enter to return to the main installer.:
got same issue as well
I have established only on the 6th attempt.
Question: Where are all these files?
I have an empty folder
Workflow :
TXT to VIDEO
IMG to VIDEO
StartEndFrames
Face to VIDEO
VIDEO EXTENSION
VIDEO to LOOP
Frames interpolations
Upscaler
Video merge
At first there were 40 GB on the disk. For some reason it copied my folder with models. Now there is 0 GB on the disk. Now there is chaos somewhere models of 1 KB, somewhere normal. The script stopped. Lol. How much disk space is needed to run this script? Probably some warning is needed?
This script allows you to choose what you download, if you choose everything there is more than 1 TB...
UmeAiRT Yes, the script asked what to download, but for new models.
Good news. All models in the old folder are not damaged. There will be no hell of downloading models again. But it is better to run the script with an empty folder for models.
UmeAiRT The script worked well when I made an empty 'models' folder. 1 TB was not needed. :-) It is better if the script does not suddenly copy a 'models' folder with 90 GB of all sorts of garbage. And it could have been more, I have recently been using ComfyUI
Its dont Clean RAM (WAN 2.2 t2v)
64GB RAM
Batch of 10, 4 generate fine then PC freeze because 100% RAM Full.
Edit: 100% RAM Usage (64gb) VRAM 50% Usage (32GB)
VRAM are Fine
Pleace Fix :(
So or So thanks for your Work, Review and a little Buzz for you :)
I don't understand what you're talking about. It's an installation script and you seem to be talking about a workflow?
UmeAiRT Oh, sorry, yes, it was posted incorrectly. It's “TXT to VIDEO simple workflow WAN2.2.”
My PC crashes after 3-4 generations because the RAM is completely full, while the VRAM is only 50-60% full.
Regardless of whether I have interpolation on/off or upscaling, it happens when the video is saved. (Hard drive is not full, over 2 TB free.)
Edit: Found the Problem, the Base Upscaler was the Problem. Edit/Replace the Upscaler node now works fine.
Launching Python script...
Failed to execute startup-script: D:\ComfyUI-Omni\custom_nodes\ComfyUI-Manager\prestartup_script.py / No module named 'aiohttp'
Prestartup times for custom nodes:
0.0 seconds: D:\ComfyUI-Omni\custom_nodes\rgthree-comfy
0.0 seconds: D:\ComfyUI-Omni\custom_nodes\ComfyUI-Easy-Use
0.0 seconds (PRESTARTUP FAILED): D:\ComfyUI-Omni\custom_nodes\ComfyUI-Manager
Traceback (most recent call last):
File "D:\ComfyUI-Omni\ComfyUI\main.py", line 145, in <module>
import comfy.utils
File "D:\ComfyUI-Omni\ComfyUI\comfy\utils.py", line 30, in <module>
from einops import rearrange
ModuleNotFoundError: No module named 'einops'
get this after installing the 3.2 Install script and trying to run the ComfyUI
You can send me install_log.txt to see which is not installed correctly
Hey there,
used the script in the past and it worked perfectly.
But with the V3.2, the tools seems to not download any models.
Is there any solution for this?
Greetings
Good evening,
I haven't changed the method for downloading models, but if you give me the name of the one causing the problem, I can check manually. The overall problem seems to be Hugginface, which is increasingly restricting downloads for people who aren't logged in. The site seems to reject requests that seem suspicious. Unfortunately, I don't have an alternative solution for hosting more than 1TB of model files.
UmeAiRT Hey, thank you for your response.
I can't identify a direct one, that is causing the trouble.
When i select the wanted packages, it says "Downloading xxx" . But in the background, there isn't downloaded anything.
Is there maybe the possibility, to login into my hugging face account, so that the tool can use the credentials.
But good to know, that your are hosting all the packages in your own hugging face. So the workaround for me could be downloading the packages manually from your well structured folder hierarchy.
Thanks a lot
@Clovnix getting this too, it says its downloading models but it downloads nothing
Works for me, thanks for making this!
Spent 6 hours trying to get SageAttention (and Triton) to work prior to this, glad to finally be over it.
Now its time to experiment with workflows for my system!
I can confirm this and I’m really happy now!
Thanks for the automation. But I have a question.
Previously, I downloaded previous versions of your installer and everything was fine in terms of RAM usage.
Now with workflows for Wan 2.2, the RAM is completely filled (32 GB), but the video memory of the video card is not completely filled (9/12 GB).
Because of this, there is a slowdown, the Windows swap file is used. Why could this be and if you can advise some parameter to register in the autostart of the comyiui
Have do fresh comfyui install and use v3.2 bat. All looks good & and have updated confyui too. But qwen workflows make now black photos. And only "Auto" settings on "Patch Sage Attenion KJ" works, other choices makes error. I remember, there is error building sage wheel (v2), so i used sage v1, maybe error there too. Or it was triton wheel... Any ideas how to fix?
I tested more "Auto" setting not give any speedup, so it not working at all.
simply f amazing dude... though the installer is... way too optimistic... FP16 and BF models or anything about Q5 won't really run on sub 16gb of ram... also you might want to put a node that... users will still need monster regular ram and probably tweak their offloading and quant parameters on some nodes.
anyway... using FP8 with my RTX 4078 Ti Super... AMAZING results... now wondering if i can stick this with framepack for 90s long generations....
right click run as admin, change the path for folder and dont just hit enter.
Got some french error about wheels and xformer
Failed to build xformers
error: failed-wheel-build-for-install
I get the same thing.. and essentially Sageattention still isn't installed at the end of it, so I assume it's a serious error!
i send a fix today can you try again or send me install logs ?
What VRAM and RAM it need?
!!! Exception during processing !!! [enforce fail at alloc_cpu.cpp:121] data. DefaultCPUAllocator: not enough memory: you tried to allocate 9172942848 bytes.On 3060 12G and 48G RAM...
What workflow and model did you try to use?
IMG to VIDEO (gguf) with recommended models. Stopping somewhere after genrating initial video. So - that's not VRAM problem. May be problems with SWAP-file? Max 6G is OK?
- ERREUR: La commande a Г©chouГ© avec le code 1.
- Commande: python -m pip install torch==2.8.0+cu129 torchvision torchaudio --index-url https://download.pytorch.org/whl/cu129
- Sortie de l'erreur:
Looking in indexes: https://download.pytorch.org/whl/cu129, https://pypi.ngc.nvidia.com
python.exe : ERROR: Could not find a version that satisfies the requirement torch==2.8.0+cu129 (from versions: none)
строка:1 знак:1
+ & "python" -m pip install torch==2.8.0+cu129 torchvision torchaudio - ...
+ ~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
+ CategoryInfo : NotSpecified: (ERROR: Could no...versions: none):String) [], RemoteException
+ FullyQualifiedErrorId : NativeCommandError
ERROR: No matching distribution found for torch==2.8.0+cu129
- ERREUR FATALE lors de la tentative d'exГ©cution: python -m pip install torch==2.8.0+cu129 torchvision torchaudio --index-url https://download.pytorch.org/whl/cu129. Erreur: L'exГ©cution de la commande a Г©chouГ©. VГ©rifiez les logs.
Have you tried running the script "as administrator"? Because the link works correctly :/
@UmeAiRT Yes, I ran it as administrator. It always errored in the same place. I reinstalled NVIDIA, Python, and other software that I usually use for ComFayUI. Version 3.2 installed without problems, but everything above it had the same error and got stuck at one stage. The problem might be that some resources are blocked in my country. Links open directly, but the error comes from the script.