**Don't forget to Like 👍 the model. ;)
GGUF: https://huggingface.co/city96/Wan2.1-I2V-14B-480P-gguf/tree/main
https://huggingface.co/city96/Wan2.1-T2V-14B-gguf/tree/main
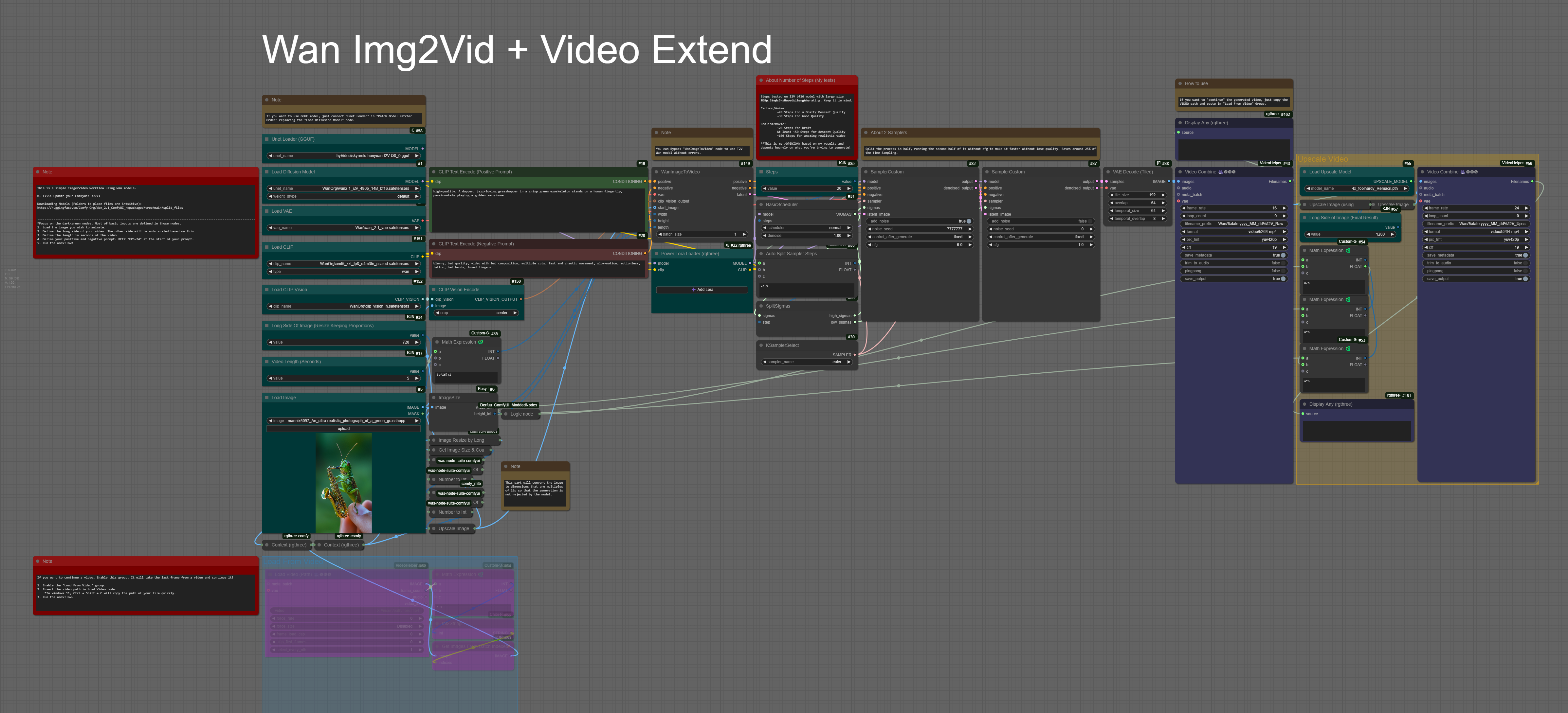
This is an Image-to-Video workflow using the new Wan-AI Img2Vid model!
Very consistent and generates videos at 16 FPS. I also added the "Extend a Video" function to this workflow—simple to use.
As always, instructions and links are included in the workflow. Just make sure to update ComfyUI and the required nodes before running it! You will need at least 16GB VRam to run it descently.
Worth it? Is it better than Hunyuan? Well... I think it is.
That’s it. Leave a like and have fun! 🎥✨
Description
First Release
FAQ
Comments (85)
Sampler Custom Error: mat1 and mat2 shapes cannot be multiplied (512x768 and 4096x5120)
Comfy updated? Are you using Img2Vid model? Which node do this happen?
@Sam_A I have the same in SamplerCustom
I have the same problem.
same here at sampler custom mat1 and mat2 shapes cannot be multiplied (77x768 and 4096x5120)
Same. Solution?
Thanks man..
I have tested both Kijai and comfy native wf and yours is the best and fastest.
how can I contact you? do you have discord?
Yeah I have discord: goldencrow777
Or you can send diret message in here :)
Im not sure if you are aware of this but, there is a better way to split the sigmas, Kijai created a node for this called "scheduled cfg guidance". Without using 2 samplers u gain the speed that is wasted when one sampler switches to the other, here is one of your previous workflows with that change, u can implement it here if you want:
https://pastebin.com/TuRik9YJ
Wow! That's interesting! Thanks for show me this! As much as I love what kijai do, sometimes his nodes cause a lot of problems for general public due to complexity of instalation, etc. But In this case I don't see a drawback! i'll add this for sure after I test. Thank you!
Edit: Fantastic! After testing it, it's amazing! I'll update my workflows as soon as possible with this feature!
@Sam_A great ^^! im a fan of your workflows btw, i like how easy it is to change the resolution of images with them, I don't like manually adding both width and height xD
@Mikusha Haha! Thanks! Well, I'm not a big fan of changing resolution manually as well. Hence I always endup making my own workflow and share i nhere for the ones who are "lazy" like us.
@Sam_A @Mikusha using kijai sampler node speed up the inference? if yes what is the % approx?
thanks
@kg_09 Not really a speedup, but makes the workflow simpler... Instead of divide stepst in 2 samplers, kijai node can divide the Steps with and without CFG in one single sampler.
in the default setting it ignored the input image, and created a new video. I think this workflow is wrong, plus it takes 50 seconds per iteration. I have another one posted here on civitai that takes only about 10 seconds.
Change, cfg, seed. You will get different results. Depending on the image, any I2V model can do deform original image to create a different video. It's all about config, prompt and what are you trying to create.. The time per interaction depends on the latent size you define, also the length of the video. My workflow come as default with 720p as large size, which is large for video generation. If you change it to 512, like most of the workflows around, the time will go down to 10 seconds per interaction. You just need to pay attention to inputs.
Hey, I'm trying out the workflow and am testing out some of the GGUF models. I swapped out the load diffusion model node with the load unet node, but that results in error "ValueError: Unexpected architecture type in GGUF file, expected one of flux, sd1, sdxl, t5encoder but got 'wan'"
You have a note which says "If you want to use GGUF model, just connect "Unet Loader" in "Patch Model Patcher Order" replacing the "Load Diffusion Model" node.
However, I don't see the Patch Model Patcher being used in the workflow. I have that node installed though. I'll try hooking it up, just wanted to make you aware
The GGUF models for now, If I'm not wrong, are only TextToVideo, so to run it you need to bypass the "WanImageToVideo" node and use the workflow as a TextToVideo instead of ImageToVideo. Once they release the GGUF Img2Vid, it will work. I just got ahead with the notes because this workflow is similar to a previous workflow I have.
@Sam_A there is I2V 480p already ^^
here: https://huggingface.co/city96/Wan2.1-I2V-14B-480P-gguf/tree/main
@Mikusha Great. Just tested it! Update the "Unet Loader (GGUF)" package and it will work. They added wan support in latest version. And conect it in Power Lora Loader (The node the ChackpointLoader was conected).
Thanks! Also, you have a note saying to "KEEP fs-24 at the beginning of your prompt" but I don't see it being used in the example workflow
@Kiefstorm AH. My mistake. This is from an old workflow. This one don't need this.
Hey Sam! It's working great so far, thanks in advance. A little confused on the extend video group. I am trying to extend the video by copying and pasting the path, im not sure if im doing this correctly, but i'm getting an error with load video (path) node - What settings should i have in there?
When you paste the path in "Load Video", it will start to play your video as a preview, just like in "Video Combine". If the video don't start to play, something might be wrong with the path or format. Do you have the error for me?
Once it load the video, you just need to run the workflow and it will work.
Hi, @Sam_A . I have the same issue "SamplerCustom mat1 and mat2 shapes cannot be multiplied (77x768 and 4096x5120)" in SamplerCustom .
Hey, how do you get T2V to work? I bypassed WanImageToVideo but now I can't run the workflow since the SamplerCustom needs something in "latent_image" to run
Ah. It was a Mistake I forgot to fix in this workflow. If you want to run it as a T2V you can just add a node called "EmptyHunyuanLatentVideo" and connect it to the sampler. You can get width, height and length from the old "WanImageToVideo" node.
Sorry. My bad.
Are 16GB of VRAM crucial? My comfy just stops working and pauses himself when i try to generate anything. I have RTX4070 with 12gb. At first it gave me a page file size error, so i bumped up my virtual memory. Now in doesn't even show any errors, just pauses itself after loading all models, clips and VAE
@Meenouse It's possible to run it with 12GB. Use a GGUF model, Q4 or Q5. Start with small "large size". 512px or 480px. And only 3 seconds length. Once you're able to get a result, ou can raise the values until the limit of your GPU. I don't remember the settings I run it in a 4070. I can chekc it later and tell you.
@Sam_A It would be super helpful. Thank you!
I'm running this on an Nvidia RTX 2060 Super 8GB. I'm using the 5Q_K_M gguf model. Everything is pretty stable on 20 and 30 samples. I tried rendering both 3 and 5 seconds of video. i2v works, t2v is also fine. The only thing is that for t2v I had to add the EmptyHanyuanLatentVideo node and replace Load Image node with it.
I'm using the RTX4070. My main setting are, wan2.1-i2v-14b-480p-Q3_K_M.gguf model, 20 steps, length 81 (5 second video) takes about 27 minutes. Not using this workflow. Try a basic workflow to see if that will work. https://github.com/comfyanonymous/ComfyUI_examples/tree/master/wan
I dont understand your text that says "Split the process in half, running the second half of it without cfg to make it faster without lose quality. Saves around 25% of the time Sampling." when I try and load an image the sample custom box goes all green and pixelated. Do I bypass this or drop the noise to 0? FWI I have RTX 2070
Try to run it with original config. The text is just an explanation why the workflow uses 2 samplers. The second half of the sampling can be with cfg 1, which saves time.
You can't get any video from the workflow?
How do I better animate illustrative art better? Currently, I am trying to create a meditating cat. It works well when I use an image where the cat's eyes are open but when I give it an image where the eyes are closed, I get absolutely no movement whatsoever. My prompt includes "fur wind movement", "leaves moving around body", etc. Is there a particular lora I can use for this? Thanks for the help!
Well... This is very specific. I also had problems trying to animate a little cute grass animal/monster when I was starting. I tried to change the prompt sometimes. In the end it's more like try and error. And if you can find a Lora with the movement you need or something similar, Yeah... This is the way. It's all new so I don't really know. I'm trying just like you. Hehe.
Your note says "4. Define your positive and negative prompt. KEEP "FPS-24" at the start of your prompt." but the prompt does not have FPS-24. IIRC this is only useful for skyreels and not wan, though, perhaps a leftover?
Yeah. It's not necessary. In fact Wan works at 16 fps. I just forgot to remove it. lol
Hey Sam, this workflow works fine for me. Only one issue: when generate the 5 secs video, the 4th sec frame alway Overexposure. I tried more than 20 different photos, the results always the same. Is there a way to fix this issue? Thanks
AH. it's a problem with "VAE Decode (Tiled)" If you have enough memory, replace for the original Vae Decode and the problem will be gone. I'll update the workflow later.
Thank you so much!@Sam_A
@Sam_A Hey OP! Love this workflow <3 Currently experiencing the same issue with this overexposure. I want to create a video loop but it's quite jarring due to overexposure at the end frames. I've already swapped it to VAE Decode (not tiled) but still experiencing the same issues. Any tips?
Also I added a start-end frame workflow on my end, but not sure if you have anything like that in works?
@drukware So, the Normal Vae decode, solved this problem for me. But If I'm not wrong, the basic Vae Decode also split the encoding in Tiles if you have no enough memory to decode it at once. It could be this.
About Start-End Frame, I still didn't touch it yet. I'm giving it a time until I make sure everything is stable, because we end up with a lot of trash files in HD after the whole revolution of the model happens, and I'm trying to avoid it. lol
Wow, thank you very much for this, it's so helpfull and easy to use !
I've been trying to modify it to have both a 24 and a 16fps video as a result of the upscale (sometimes, the 16 fps is really better), but I really need to improve my understanding of comfyUI :D
Wan is made to generate 16 fps in general. So 16 fps usually will be the best way to go. After that you can interpolate frames to reach the FPS you wish for final result! :)
This is the best image2video workflow i've tested so far. Congrats! I'm trying to implement a random seed for each execution, but I don't know how to do it right. any ideas?
Thank! In the first sampler, change the "control_after_generation" from 'fixed' to 'random', and you will get random seeds.
I've tried lots of I2V workflows but this one seems the best to me - can an interpolator be added after the upscale please?
Yeah. It's possible. I need to update this workflow. Once i do it, I'll add one.
@Sam_A Thanks so much
At first: thaaaaanks - this workflow is so wonderful <3
For interpolation I added a "RIFE VFI" node from "comfyui-frame-interpolation" just before the last Video Combine node. Multiplier set to 2 - apparently it is an int field and not float, so the video will be a little bit longer than the raw version (you could also set final framerate to 32 to keep same length)
@BubbleButtPrincesses Added interpolation to the workflow.
@Sam_A Thank you!
Guys can please somebody help!never use before comfy and wanted to try to make videos but dont understand how everythign works, and there is no normal tutorial
If you follow the instructions in the red Note you might be good to go. It's very simple to use.
@Sam_A Sorry what red not? i dotn see any red note on page?
@matriksAi A big red Node with Instructions at the left of the workflow.
I am preparing a solution on this very soon. just follow me and wait 10 days
@aimodelmaya Solution for what?
@Sam_A see new users are often lost in comfy ui flows and its a steep learning curve. So I am preparing something for non techy guys
@aimodelmaya Ah! Cool! Like a Tutorial?
@aimodelmaya Any news about your solution that yo uwant to prepare?
Every time I put a new video to extend it get's a bit darker than the previous one any clues of how to fix this?
Not possible atm from what I know. Wan changes the color of the frames a little bit. It will only be posisble once we have a I2V that don't change the image saturation so much. I usually correct it in a video editor to join the videos.
You said "*In windows 11, Ctrl + Shift + C will copy the path of your file quickly."But I'm on cloud,set the path but it's not work——WARNING: [Errno 2] No such file or directory.No way the path is wrong"/{folder name}/105942_OG_00001.mp4.Are there any ways I can just load the video?
Hmmm... You can replace the "Load Video (Path)" for a "Load Video (Upload)". It will work.
@Sam_A Thanks.
Will you be updating anytime soon Sam like adding Tea cache?
Just did! :D
Please add the Cache for Tea c:
Done!
@Sam_A Can i enable everything or will it be stuck at generating?
@Santaonholidays It all depends on your PC... How much Vram, which model are you using, Large size of Image, Video Length, etc...
@Sam_A RTX 4090,i'm having the same models as you do and the image size is like 500-800,5 seconds maximum
@Santaonholidays So, I also have a 4090. I use it with the original config in the workflow. For a rectangular image (5:8 or 9:16) you can use the large size as 720 and 5 seconds, and it might work with sage. To use Teacache I think you need to reduce this a little bit... You can also try to use some GGUF smaller model. Q6 do a fine job in my tests.
@Sam_A So i can use everything but gotta reduce the TeaCache? Reduce it to which settings? :D
@Santaonholidays I'm not sure. I Don't remember the values to make teacache work. I suggest you to start trying to generate a video with 512 large size and 3 seconds. Then you go up until the GPU cannot handle it anymore... lol The teacache you can leave as default for the type of video you're generating. T2V or I2V have diferrent setting...
@Sam_A Can you upload your workflow youre using for 5:8 Portraits please? :D
@Santaonholidays It's the one I uploaded. I just don't use TeaCache. It's using the config I use for 5:8 Images. But it's really tight. If I open a second program that uses even a bit of the GPU, the generation time goes up sky rocket. With this setting I usually close everything else, turn off internet and leave it generating 4 or 5 videos, so I can pick the good ones after it finish the work. It takes around 6 minutes for normal generation and 2~3 with fast lora. But If I use Vram with anything else, the time goes up like hours. So I stop the work, close everything else and start again.
@Sam_A For me most of the times it gets stuck but when i keep closing the .bat off and on it works :D
@Santaonholidays I use Crystools to check my PC usage on comfy. So I can adjust the workflow to what my PC can handle easilly. Once you see the resources used on screen, you will have a better idea on how to adjust it. I cannot tell you so much because it really changes from PC to PC. The best advice I can give you is, start with small length and small "large size of image", and go up slowly, until you understand what your specific case can handle. Also try with different image shapes. Square ones are the worst, becuase it resize to maxSizeXmaxSize, which is the worst case scenario for Vram usage. I uploaded the workflow with the cofig I use in my 4090 for rectangular images. And as I said, I close everything else, so it don't get stuck. It really take the 4090 to the limit in this config.
@Sam_A Maybe one day i will get the Chinese 4090 48GB VRAM :D
@Santaonholidays It's the dream XD I wish I could afford one of those server GPUs made of Unobitanium... With Gigallions of Vram...
@Sam_A Maybe my 1k Buzz reached 0,01% of your dreams :D
@Santaonholidays Haha! Thanks a lot! :D