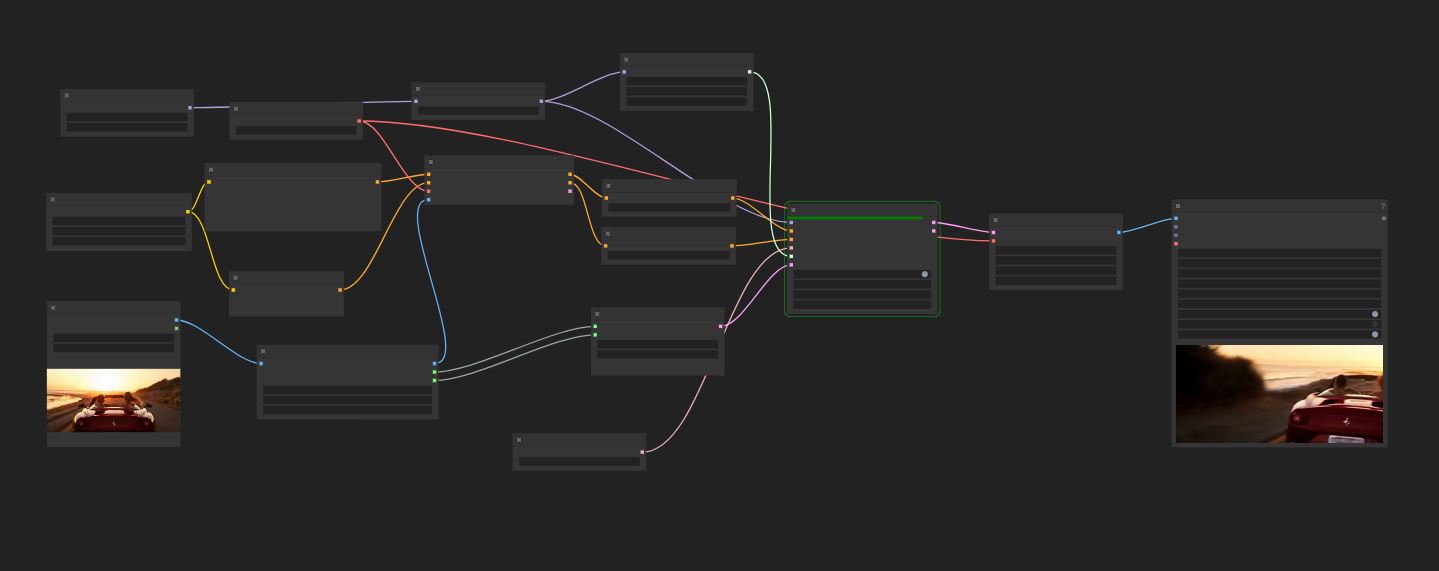
A basic workflow for the native implementation of SkyReels-V1-Hunyuan-I2V in ComfyUI
Description
FAQ
Comments (60)
Say how much vram it needs :)
probably about the same as Hunyuan base, it's a retrain of Hunyuan with special capacity
Error(s) in loading state_dict for HunyuanVideo: size mismatch for img_in.proj.weight: copying a param with shape torch.Size([3072, 32, 1, 2, 2]) from checkpoint, the shape in current model is torch.Size([3072, 16, 1, 2, 2]) error for loading any of the KJ reels models in that loader.
Update the ComfyUI and you are good.
@czxck001949 Updating didn't work for me
@Jaya1010 go in the update folder of your comfyUi, you should have a .bat file with update comfyUI and all python dependencies (or something like that) I clicked this one, it installed a bunch of stuff and it work now (but warning, It probably broke other stuff, I'm sure I will have surprised in my other worfklow that will surely now for some of them don't work anymore)
Error(s) in loading state_dict for HunyuanVideo: size mismatch for img_in.proj.weight: copying a param with shape torch.Size([3072, 32, 1, 2, 2]) from checkpoint, the shape in current model is torch.Size([3072, 16, 1, 2, 2]).
yeah got this error as well (or something that looked like this error) didn't go beyond model node
go in the update folder of your comfyUi, you should have a .bat file with update comfyUI and all python dependencies (or something like that) I clicked this one, it installed a bunch of stuff and it work now (but warning, It probably broke other stuff, I'm sure I will have surprised in my other worfklow that will surely now for some of them don't work anymore)
Can you also upload or link the image used?
Where to download skyreels_hunyuan_i2v_fp8_e4m3fn model?
thanks.
Did you obtain the diffusion model from here?
https://huggingface.co/Kijai/SkyReels-V1-Hunyuan_comfy/tree/main
What is SKyreel ? is that Hunyuan V2 or something ?
it's a custom finetune of hunyuan, it's not the official hunyuan i2v, but a custom i2v finetune
got this error
RuntimeError: shape '[1, 32, 13, 80, 60]' is invalid for input of size 998400
If you have added teacache, delete it.
I get similar kind of error right from the checkpoint node (it doesn't even go further) tried BF16 and fp8 models, no luck, I suspect this is a comfyUi portable limitation, I'm talking about the I2V model, the T2V one seems to work (in a strange way, kinda blurry)
go in the update folder of your comfyUi, you should have a .bat file with update comfyUI and all python dependencies (or something like that) I clicked this one, it installed a bunch of stuff and it work now (but warning, It probably broke other stuff, I'm sure I will have surprised in my other worfklow that will surely now for some of them don't work anymore)
@dio011 what's wrong with teacache patch?
@NoArtifact I used Stability Matrix packages manager and ComfyUI auto update every single new commit when starting up.
@kaytransg196 I got a shape error when adding a teacache node. I deleted the teacache node and was able to create the clip normally.
For those with Error size/shape tensor blabhlabh etc... go in your comfyUI update folder, and click on update comfyUI and all python dependencies .bat file (or some similar named .bat file) solved the issue for me, BUT WARNING? IT MAY BROKE OTHER WORKFLOW, so do it only if you don't care of eventually reinstalling another comfyUi for specific workflow...
You were right, it broke my other workflows
Regardless of the starting image, the prompt, the settings and the attempts, I have never managed to obtain a remotely sufficient result.
Has anyone had better luck?
I have yet to obtain one result that I would consider barely acceptable... But I test things that probably shouldn't be tested at this stage (like putting some hunyuan loras in the mix)
@NoArtifact loras bust it up, the # blocks in skyreel is larger (i think 2x) that of the base hunyuan. when I tried a lora it made a glitchy mess. It won't outright, fail, but the output will be garbage. We likely need a new lora block scientist to figure out which to enable/disable to use base loras.
that our we need new loras trained on this finetune
@psspsspsspssspss yes probably right, I tested with no loras and still have an hard time to get something good though... seems extremly hit and miss
I got only good results with the input pics from Cyberfolk. All my inputs resulted into "2000 bc" garbage. No clue why.
It works but I haven't gotten good results with it yet. May be a skill issue on my part, I'm not familiar with prompting that InstructPixToPixConditioning node. The results I've gotten so far (only played with it for a little bit) are sometimes choppy/glitchy or have little movement of the main subjects, or just look kinda bad in general. There is definitely potential here and I'm probably doing something wrong, if anyone has tips for prompting or best settings that would be great.
It would be nice for those obtaining good results (if anyone does) to post it here so we can all learn from their settings indeed, so far my results occilate between boring no movements, or blurry mess, or simply messy garbage, not a great start...
The result depends somehow extremely on the input picture. I am still testing
Successfully run through,A lot of errors are also because of the size of the scale,Just change the value,After joining wavespeed,3060 8G,77 frames only took more than 2 minutes,Thank you for your work,Good job,I admire kj,But its workflow will keep making my card oom.,
Are you using gguf models? How are you getting 77 frames in two minutes on a 3060 8GB? I ask you because I have the 12GB version and it is taking way longer than that.
@Yulexuan I have a 12gb RTX 3060, I was using safetensors models and the generation bar took about 15 minutes, but when it reached the end, confyui froze and didn't generate anything, I had to close it because it was frozen, if you're lucky I hope to hear from you and hopefully we can use .gguf models.
This works better than leap fusion
in some aspect, yes
I have yet to see it, but if it does, it's not that difficult to do better :) leapfusion was the biggest letdown I came across lately (but to be perfectly honest, maybe I was using it wrong...)
That's encouraging, but I'm having some trouble getting much non-glitchy motion. Mind sharing what parameters you changed from the default settings? Guidance, steps, denoise, resolution, etc?
@sixpt55 it's amazing how little to no info there is about all those thousands of nodes that people spread around... Such a fucking pain in the ass having to test for hours to maybe figure out what this and value do.
The downside is that it does not support fast hunyuan or lora for me
This workflow is the first one I have been able to get working with Hunyuan besides using Pinokio (that doesn't support I2V). The prototype I2V that is currently available isn't really working (from what I'm getting), it's almost more like the image is used to point it in the general direction you want to go. The prompt still seems to have the most influence. Overall, I like Hunyuan better than CogVideoX because people don't become horrific twisted monsters near the end. And the motions are more natural. Cog's picture quality was better, but it took a lot of generating and I ended up usually picking a video with just slight motion and zooming in. I have big hopes on Hunyuan getting better, especially if it ends up natively supporting I2V. To dumdidum, thank you for this workflow. Good work.
Actually, I was using the T2V model, that's why the output didn't look like the input image. For some reason, the FP8 model gave me errors. The FP16 model worked just fine. I have only generated one clip with it today, but it worked fine and looked like the input image. The motion was kind of boring, but I think I can fix that with better prompts. I was just testing to get something working properly. I may update again.
Where do you find the missing nodes?
Error i2V model:
Error(s) in loading state_dict for HunyuanVideo: size mismatch for img_in.proj.weight: copying a param with shape torch.Size([3072, 32, 1, 2, 2]) from checkpoint, the shape in current model is torch.Size([3072, 16, 1, 2, 2]).
Any idea?
go to your update folder on ComfyUi, and run update comfyUi and all python dependencies .bat file
I'm also having the same problem. latest comfy, updated everything
@GitarooMan did you updated through the bat file I mentioned ? updating from comfyUI manager wont cut it
Oh, I see. I didn't know the Update by Manager was less reliable. Indeed, there were more updates and that solved it, thank you so much!
Solution for comfyui standard is 1st: pip install --upgrade torch torchvision torchaudio --extra-index-url https://download.pytorch.org/whl/cu126 then update all through comfy manager (other nodes and dependencies).
we need fast hunyuan for this !
Note from developer: When generating videos, the prompt should start with "FPS-24, " as we referenced the controlling the fps training method from Moviegen during training.
Indeed, but I have the feeling they over estimate the importance of that trigger (even if it's probably best practice to put it still) , I've tried with and without, didn't see much differences (and so far not a single video was good anyway)
awful results with hd images as input, if someone something acceptable let us know
Please help? I am always getting this error with Skyreels
InstructPixToPixConditioning
'VAE' object has no attribute 'vae_dtype'
Error(s) in loading state_dict for HunyuanVideo: size mismatch for img_in.proj.weight: copying a param with shape torch.Size([3072, 32, 1, 2, 2]) from checkpoint, the shape in current model is torch.Size([3072, 16, 1, 2, 2]).
Simply put, if neither updating torch, nor reinstalling hunyuan, nor forcing comfyui to update helps, then you need to manually make changes to the three .py files mentioned in this link: https://github.com/comfyanonymous/ComfyUI/pull/6862/files
How does anyone get this to work? How do you find all of the missing nodes?