




大変申し訳ありません!ジャンピング土下座案件です!
.debファイルのパッケージビルドする際に前Ver.の0.2.5.3のままビルドしてました...orz
お手数をおかけしますが0.2.5.4を再ダウンロードお願いします。
I'm so incredibly sorry! This is a full-on apology situation! When building the .deb package, I accidentally built it using the previous version, 0.2.5.3... orz I apologize for the trouble, but please download version 0.2.5.4 again.
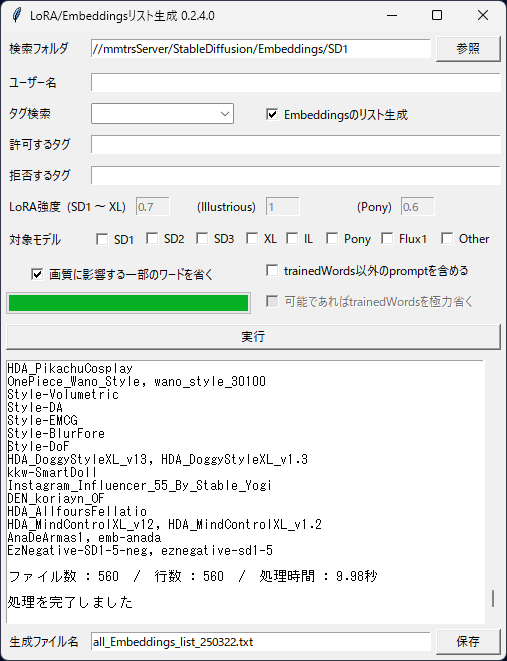
指定したフォルダ内にあるLoRA(.safetensors)、Embeddings(.safetensors, .pt)のリストを生成します。
生成されたテキストファイルをDynamicPrompts等のWildcardsフォルダに入れてご活用下さい。
一応、Windowsが日本語以外の場合は英語表記になるはずです。
使い方
検索フォルダ...リスト生成したいLoRAやEmbeddingsが入っているフォルダを指定します。指定したフォルダ内にサブフォルダがあっても無視します。サブフォルダ内にもリスト生成したいLoRAが入っている場合はそのサブフォルダも個別にリスト生成して自力でリストを結合するなりしてください。
ユーザー名...リスト生成したいLoRAの作者(civitaiでのユーザー名)を指定してください。複数の指定は出来ません。ユーザー名が空の場合は全LoRA作者が対象になります。 (パス名として不適切な文字は削除されます)
Tags検索...リスト生成したいLoRAの種別(Character/Style/Poses/Clothing/Concept/Background)を選んでください。animeやsexyなど手打ちも可能です。複数の指定は出来ません。0.2.2.0追加のCharactersを選択で"Character,Style,Poses,Clothing,Concept,Background"の何れも記載がないモデルをCharacterとして扱います。
許可するタグ...タグ検索がヒットして且つ許可するタグで検索します(カンマ "," で複数指定可、その際はORになります)。 タグ検索が空欄の場合は許可するタグでOR検索できます。同時に拒否するタグを指定すると更に絞り込めます。 タグ検索と拒否するタグに含まれるタグは指定出来ません。
拒否するタグ...タグ検索と許可するタグでヒットして且つ拒否するタグを除いて検索します(複数指定はORになります)。 タグ検索が空欄の場合は全検索から拒否するタグを除いて検索できます。 タグ検索と許可するタグに含まれるタグは指定出来ません。
Embeddingsのリスト生成...そのままの意味です。.safetensors以外の.ptファイルにも対応したハズです。
LoRA強度(SD1 ~ XL)...Illustrious系以外の時に反映される強さです。
LoRA強度(Illustrious)...Illustrious系の時に反映される強さです。
LoRA強度(Pony)...Pony系の時に反映される強さです。
対象モデル...全部レ点なしで全てが対象になります。XLとILとPonyは同時使用可で、Otherは全てと同時使用可です。一部の方がLoRA等をOtherとかで公開してる方がいて(SD1のBra使用の方とか).civitai.infoだけでは判別しきれないので同名の.JSONファイル参照したり同名の.safetensors本体の内部参照して可能な限り判別します。0.2.2.0より生成ファイル名にも記載されます。
画質に影響する一部のワードを除く...そのままの意味です。リスト生成する際にmasterpieceやbest qualityやscore_?等をそのまま含めるか省くかです。完全に除くのは無理で稀に誤認識で正常にプロンプトを抽出できない事があります。ガチャで画像生成しておかしいな?って感じたら自力で修正してください。
trainedWords以外のpromptを含める...そのままの意味です。リスト生成する際にpromptの記載をそのまま含めるか省くかです。自分的にはCharacterのリスト生成時は含めますがStyleなどはtrainedWordsのみにしてます。ネガティブプロンプトは全無視です。
可能であればtrainedWordsを極力省く...このオプションをオンにしてあってもプロンプトの記載がない場合はtrainedWordsの内容を反映します。
生成ファイル名...生成したリストを保存するファイル名(.txt)を指定します。上記のユーザー名とLoRAタイプから勝手にファイル名が変更されるのでそのまま使うなり修正するなり全消しして手打ちするない好きにして下さい。手打ちした後にユーザー名やTags検索を弄るとせっかくの手打ちが消えるので注意してください。
実行ボタンで生成します。生成ファイルの保存先に同名のファイルが有っても問答無用で上書きするので注意してください。
バージョン0.1.0.0で仕様変更し、生成しただけではファイルの作成はされません。生成した後に生成ファイル名の保存ボタンを押して保存してください。
* 一時停止ボタンは未実装です。 0.1.1.0で実装しました。
* Pythonからのコンパイルで電子署名もしていないのでセキュリティソフト等でウィルスやマルウェアの誤検知があるかもしれません。サポートできないのでその場合は使用を諦めてください。
* Flux1のLoRAリスト生成は対応しておりません。対応しません!...対象モデルにFlux1とありますが、たぶん生成しても滅茶苦茶で使えないかと...
* 私個人が使いやすいように制作してあるので機能追加やバグ修正依頼などは一切受け付けません。自己責任で使用してください。
* 生成した後、結果が空でも空ファイルを保存できてしまう間抜けな状態ですが許してください。気が向いたら修正します。 0.1.1.0で対策しました。
:
:
:
Generate a list of LoRA (.safetensors) and Embeddings (.safetensors, .pt) in the specified folder.
Please put the generated text file into the Wildcards folder of DynamicPrompts, etc.
The file should be written in English if your Windows is not Japanese.
How to use
Search Folder... Specify the folder containing the LoRAs and Embeddings for which you want to generate a list. Subfolders within the specified folder will be ignored. If the sub-folder also contains LoRAs you wish to generate a list of, please generate the list of the sub-folders individually and merge the list by yourself.
User Name... Specify the author (user name in civitai) of the LoRA you wish to generate a list for. You cannot specify more than one. If the user name is empty, all LoRA authors will be targeted. (Characters that are inappropriate as path names will be deleted.)
Tags Search... Select the type of LoRA (Character/Style/Poses/Clothing/Concept/Background) for which you want to generate a list. You cannot specify more than one type. 0.2.2.0 Select Additional Characters treats models with no “Character,Style,Poses,Clothing,Concept,Background” as Character.
Allow Tags...Search for tags that hit the Tags Search and are Allow Tags (Multiple entries can be specified with a comma "," in which case they will be OR). If the Tags Search is blank, you can OR tags that are Allow Tags. You can further refine the search by specifying the Disallow Tags at the same time. You cannot specify tags that are included in both the Tags Search and Disallow Tags.
Disallow Tags...The search is performed using the Tags Search and Allow Tags, but excluding tags that are rejected (multiple hits are OR). If the Tags Search is left blank, all tags are searched except for those that are rejected. Tags included in the Tags Search and Allow Tags cannot be specified.
Embeddings list generation... It means just what it says. It should be able to handle .pt files other than .safetensors.
Strength (SD1 - XL)... This is the strength that is reflected during not Illustrious system.
Strength (Illustrious).... This is the strength that is reflected during Illustrious system.
Strength (Pony).... This is the strength that is reflected during Pony system.
Target model... XL and IL and Pony can be used at the same time, and Other can be used with all of them. Some people publish LoRA and other models (such as SD1 Bra users), so we will try to identify them as much as possible by referring to the .JSON file of the same name or the internal .safetensors file of the same name. Starting with 0.2.2.0, it will also be listed in the generated file name.
Omit some words that affect Quality... It means exactly what it says. When generating the listings, you can include or omit masterpiece, best quality, score_? and so on are included or omitted when generating the listings. It is impossible to exclude them completely, and in rare cases, the prompts may not be extracted correctly due to misrecognition. If you feel something is wrong with the image generated by the gacha, please correct it by yourself. If you feel something is wrong, please correct it by yourself.
Include non-trainedWords prompts... It means exactly what it says. When generating a list, you can choose to include or omit the description of the prompt as it is. For me, I include it when generating a list of Character, but only trainedWords for Style and so on. Negative prompts are ignored.
Omit trainedWords if possible... If this option is turned on but no prompt is given, the contents of trainedWords will be reflected.
Generate FileName... Specify a file name (.txt) to preserve the generated list. The file name will be changed without your permission from the user name and LoRA type above, so use it as it is, or modify it, or delete it entirely and do not type it in manually. Please note that if you change the user name or tags search after typing the file name by hand, your hand-typed file name will disappear.
Click the Generate button to generate the file. Note that even if there is a file with the same name in the destination of the generated file, it will be overwritten without question.
The specification was changed in version 0.1.0.0 and the file is not created just by generating it. After generating the file, click the Save button to save the generated file name.
* Pause Button is not implemented.
* Since it is compiled from Python and not digitally signed, there is a possibility of false detection of viruses and malware by security software. We cannot support it, so please give up using it in that case.
* LoRA list generation for Flux1 is not supported. Not supported! Flux1 is listed as the target model, but it is probably too messed up to be usable even if it were generated...
* I personally created this software to be easy to use, so I do not accept any requests for additional functions or bug fixes. Please use at your own risk.
* Please forgive me for the dumb state of the file, which allows saving an empty file even if the result is empty after it is generated. I will fix it when I get around to it. The countermeasure has been addressed in 0.1.1.0.
Translated with DeepL.com
Description
0.2.4.3....
対象モデル未選択で実行の際、LoRA強度が(SD1~XL)で固定されてたのを修正しました。すみません。
LoRAモデル作成者によってTriggerWords(trainedWords)の記述に癖?があって、全ワードを1つにまとめてる人や1ワードごとに区切る人やトリガー、容姿、衣服で区切る人…様々なため、現状キャラクターパック等と判断された場合は区切りごとに<lora:xxx:y>で分け、それ以外は無難に" || "で区切っていました。 それをiniファイルの設定である程度カスタマイズ出来るようにしました。 プロンプトは区切りないのでTriggerWords(trainedWords)のみの話です。
userprompts = False : TrueでTriggerWords(trainedWords)の区切りの処理をカスタムします。 Falseで今まで通り" || "で区切り下記の設定も無視されます。
userptype = ['ユーザー名', タイプ](/['ユーザー名', タイプ]...) : ユーザー名で指定したモデルのTriggerWords(trainedWords)の区切りをタイプ(0~3)にします。ユーザー名にallを入れると全体の動作になります。[]を"/"で区切り複数指定できます。デフォルトで['all', 0]で入ってますが、削除しても標準動作に変更はありません。 タイプ0は標準の" || "で区切ります。 タイプ1は", "で区切ります。 タイプ2は区切りを"{}"で囲みその中の区切りを"|"にします。 タイプ3は最初の区切りを", "で区切りそれ以降を"{}"で囲みその中の区切りを"|"にします。 タイプ2と3と下記の指定は「Dynamic Prompts」などの拡張機能を使わないと意味がありません。※"-"など5文字以上で区切ってある所は"|"に置き換えます。
optionratio = 0 : 0だと"{}"で囲むのみで"|"は付加しません。 数値指定で"{}"で囲んだ際の最後に"|"を付加して比を指定します。 0.01~0.99で空ワードの比指定になり、-0.01~-0.99で本ワードの比指定になり、1で本ワードと空ワードが1:1の比になります。
※一応解らない人向けに説明します。 本ワードが「1girl, long hair || school uniform, classroom」となっている場合、タイプ1で「1girl, long hair, school uniform, classroom」となります。タイプ2の比0で「1girl, long hair{, school uniform, classroom}」になりこのまま生成しても{}の意味がありません。タイプ2の比1で「1girl, long hair{, school uniform, classroom|}」になり"}"の前に"|"を付加することにより1:1の確率で生成時に{}内が無くなります。タイプ2の比0.5で「1girl, long hair{, school uniform, classroom|0.5::}」になり1:0.5の少?確率で{}内が生成時に無くなります。タイプ2の比-0.5で「1girl, long hair{0.5::, school uniform, classroom|}」になり0.5:1の高?確率で{}内が生成時に無くなります。 例えば「1girl, long hair{, school uniform{0.1::, panties|}, classroom|0.3::, naked, bath, bathroom}」で、のび太くんがどこでもドアで誤って入浴中のしずかちゃんの所へ出る確率位で浴室が生成され、その他低確率で学校でパンチラ?丸見え?が拝めます。 ...ま、「Dynamic Prompts」使ってる人は今更説明するまでもないですよね。
あんまテストしてないですが、例えばKing_DongさんのLoRAだと['king_dong', 3]の指定がよさげです。
:
:
0.2.4.2....
Ponyに対応しました。ILと同様、XLと同時選択できます。今のところnoobはIL扱いです。
処理完了または中止の際、処理にかかった時間を表示する様にしました。
設定をiniファイルへ自動保存し次回起動の際へ設定を引き継ぐ様にしました。実行画面では設定できない項目がいくつかあり内容は下記の通りです。
cachesize = 32 : 1つのモデルを処理中にpromptが重複しないようにするためのもので0から100が指定できます。数値が少ないとモデルによっては重複したpromptがそのまま抽出されます。数値が大きすぎても全く意味がなく、実行速度が微妙に遅くなるだけなので通常はそのままで良いはずです。
headerall = True : Trueでユーザー名の指定が無い場合に生成ファイル名の先頭へ'all_'を付け加えます。Falseではユーザー名の指定が無い場合でも付け加えません。
footerlist = True : Trueで生成ファイル名の末尾へ'_list'を付け加えます。Falseでは付け加えません。
footerembed = True : TrueでEmbeddingsのリスト生成の場合に生成ファイル名の末尾へ'_Embeddings'を付け加えます。Falseでは付け加えません。
footerymd = True : Trueで生成ファイル名の末尾へ日付'_yymmdd'を付け加えます。Falseでは付け加えません。
process_def = "01234" : 対象モデルを指定時に判定処理をする順番のデフォルト値を指定します。数値は0から4で同じ数値や誤った文字は無視されます。
0 : 対象モデルのファイル名で判定します。まめにファイル名へ"SD1"や"XL"や"pony"など自力で付け加えている方はこれが一番信頼できるし他のファイルを開かない為処理が早いです。
1 : 対象モデルのファイル名と同名の.civitai.infoファイルが存在する場合にトレーニング情報が含まれていればそれで判定します。稀に誤った情報が記入されています。
2 : 対象モデルのファイル名と同名の.civitai.infoファイルが存在する場合にname項目へ含まれていればそれで判定します。稀に誤った情報が記入されています。
3 : 対象モデルが.safetensorsでメタデータが含まれておりトレーニングモデルのハッシュ値やモデル名が含まれていればそれで判定します。マイナーなモデルは判定できません。
4 : 対象モデルのファイル名と同名の.jsonファイルが存在する場合にバージョン情報が含まれていればそれで判定します。稀に誤った情報が記入されています。
全く判定されなかった場合は"Other"扱いにします。
通常は変更する必要はないですが、例えば"03"の指定でファイル名とメタデータだけで判定します。また"4"のみだと.jsonファイルに殆どバージョン情報が記載されていないか誤った記載が多いため生成されるリストは糞です。
対象モデルタイプごとに個別に設定できます。空の場合はデフォルトが使用されます。
そのモデルが何系用なのかは全てモデル作成者の自己申告のため誤った情報が沢山見受けられますがそれらは自己責任で処理してください。
通常では全く使用用途がありませんがデバッグモードを付けました。
ユーザー名を'!'で囲う事によりデバッグモード1になります。(ユーザー名が空の場合は'!!') デバッグモード1では生成中にプログレスバーの所へ1ファイルの処理時間(秒)を表示します。
ユーザー名を'!!'で囲う事によりデバッグモード2になります。(ユーザー名が空の場合は'!!!!') デバッグモード2ではデバッグモード1の処理に加え処理中に対象モデルの(ハッシュ値)とファイル名を緑色で表示します。もしその対象モデルが.safetensorsでトレーニングモデルの情報がメタデータとして含まれている場合はトレーニングモデルの[ハッシュ値]とファイル名も青色で表示します。
ユーザー名を'!!!'で囲う事によりデバッグモード3になります。(ユーザー名が空の場合は'!!!!!!') デバッグモード3ではデバッグモード1の処理に加え処理中に対象モデルの表示は通常通りですが、実行ファイルがある場所へ"model_hashs.txt"を書き出します。対象モデルの(ハッシュ値)とファイル名を書き出し、もしその対象モデルが.safetensorsでトレーニングモデルの情報がメタデータとして含まれている場合はトレーニングモデルの[ハッシュ値]とファイル名も書き出します。
ユーザー名を'!!!!'で囲う事によりデバッグモード4になります。(ユーザー名が空の場合は'!!!!!!!!') デバッグモード4ではデバッグモード1の処理に加え処理中に対象モデルの表示は通常通りですが、実行ファイルがある場所へ"model_hashs.txt"を書き出します。検索フォルダ内全てのモデルの(ハッシュ値)とファイル名を書き出し、もしそのモデルが.safetensorsでトレーニングモデルの情報がメタデータとして含まれている場合はトレーニングモデルの[ハッシュ値]とファイル名も書き出します。