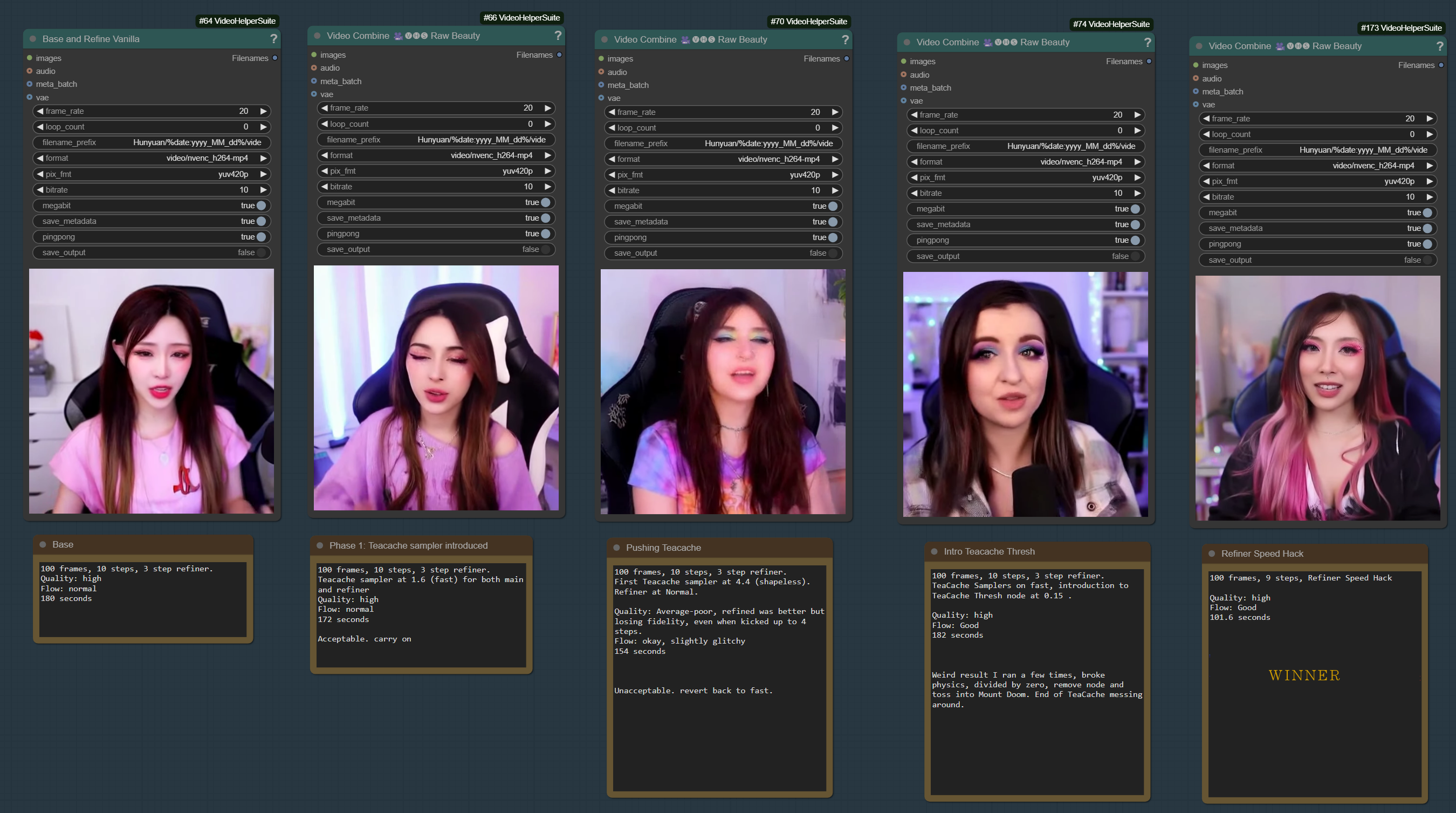
Major Overhaul. True refiner speed hack.
DeJanked Speed Hack Hunyuan T2V Final Boss:
Are you tired of your AI video workflow crawling slower than a grandma playing Frogger? Do you crave blistering speed without sacrificing jaw-dropping quality? Buckle up, because this isn’t just a workflow—it’s the Final Boss of Hunyuan T2V optimization. Through the fiery trials of placebo hacks, sanity-testing, and daisy-chain wizardry, this setup slashes render times, keeps your GPU breathing, and still pumps out e-girl-quality frames that’ll have you questioning reality. Dare to try it? It’s fast, it’s smooth, and it might just blow your mind (but not your GPU).
TL/DR:
Standard: 180 seconds (Great quality)
After Speed Hack: 100 seconds (great quality)
No descaling/rescaling
No wavespeed and minimal TeaCache.
No XL bs placebo (I feel scammed! See testing below)
This is something else (please post your results)
The testing:
Wavespeed: I will not test it due to it being dependent on Triton, which lots of people have trouble installing on Windows (and can screw up a lot of things with a windows install...those using WSL and Wavespeed can probably figure out how to shove in wavespeed for their own use. this is for maximum availability to the widest amount of users
Hardware I am using: 3090 TI 24g VRAM. 64g Ram, WSL.
100 frames, 10 steps, 3 step refiner 512x512 (no up/downscaling) for base.
Goal:
- find speed without losing quality.
- no use of upscaling or downscaling.
- no tricks, just using standard nodes to their max potential.
Method: 3 generations for each phase.
Vanilla baseline:
Round 1: (basic Vid Gen, no tweaks, just gen and refine)
Flow: normal (no glitchy movements of note)
Quality: high
180 seconds
Pass
Round 2:
Teacache sampler at 1.6 (fast) for both main and refiner
Flow: normal
Quality: high
172-175 seconds
Pass
Round 3:
First Teacache sampler at 4.4 (shapeless). Refiner at Normal
Quality: Average-poor, refined was better but losing fidelity, even when kicked up to 4 steps.
Flow: okay, slightly glitchy (possible exaggerated normal glitchyness)
154 seconds
Fail
Round 4:
TeaCache Samplers on fast, introduction to TeaCache Thresh node at 0.15.
Quality: Good
Flow: good
180 seconds (???)
Fail (pointless to possibly clashing with the sampler)
Result: having samplers in both main and refiner on fast seems to be the happy medium. possible further testing for perhaps faster settings, but will call this enough (a few extra seconds either way isn't the gains I am going for)
On to XL Workaround to kick and see whats what once and for all.
XL hack:
Gone, placebo, nerfed! 185 average. Remove and toss into fires of..etc (I feel I've been scammed!)
next up, Daisy Chain Refiner Speed Hack
results:
1 main and 2 refiner steps without encode/decode:
100 frames, 9 steps
Quality: high
Flow: good
100.34 seconds
Quality can be altered by raising or lowering a step at the beginning if desired, but 5,2,2 is producing stellar results. Recommend starting here
Why does this work?
I don't know, but I assume the first step gives shape. 2nd fleshes out, and 3rd refines. each one working off the less for less overhead and less need to start from scratch, building off the last. Alternatively, simulation universe and pixie dust...obviously.
There you have it. poke holes in it if you can.
Try it, its free, and for me, it is working blazing fast.
Some odd unique occurances come with some renders moving a bit fast (re-render same seed but drop fps down a bit)
From here, see if you can improve it...but before you run this, run your normal non weird workflow without wavespeed for your own vanilla testing to sanity test. make sure to run it 3 times though (need time for cache to warm up. by the 3rd run, you're hitting optimal speeds)
I used the hunyuan 8b 720 (fast) model and the only LoRA I had active was the fastvideo lora (found on civitai) at -0.30 (positive for big model, negative for fast models). Egirl lora added for main video model just for fun but not part of the test.
WARNING: nothing is downscaled. monitor your GPU. best to maybe go smaller. 512x512 to start, then work up (or down) from there. This speeds up your rendering time, but it doesn't lower the GPU overhead.
Description
Total rebuild:
XL out
Daisy Chain enabled
Removed all steps from start until final result double refined.
FAQ
Comments (25)
Good Morning - EnhancedLoadDiffusionModel is missing what node group is this coming from? As my missing nodes list appears empty
what number does it say? is it the lora group? (aka, you missing Loras? a triple stack right above the clip text prompt)? If so, thats RGThree, but you can probably swap it out with your favorite lora loader)
@Aicush that's from Wavespeed. You might have to manually clone that in from the repo to the ComfyUI custom_nodes folder.
@Melty1989 That was the ticket many thanks :-)
@saturngfx Ill test this out on my peasant hardware and see how I get on :-)
seen someone comment, but can't see itnow. possible wavespeed? (I don't have wavespeed in this workflow). also, not sure if I am double commenting btw, the page is being super wonky for me at the moment. But yeah, if you can either tell me the number of the node, or its location on the workflow, I can help.
@saturngfx It was the very first one for loading the diffusion model -very top left
@Aicush ahh, just the model loader. swap it out for the other hunyuan video loader if you don't have it. But yeah, that one is part of the Wavespeed stuff, however its only there because after uploading, I reintroduced wavespeed. you can swap it for the standard model loader. should have done that before uploading actually.
@saturngfx No worries got the Wavespeed pack as suggested by @Melty1989 seems to be doing the job well, will log my results on a separate post, Once I have finished :-)
My Config - 4080 mobile 12gb VRAM - 32GB RAM
Out of the box experience - Using all the same models/loras etc
I think if you stay around 480x480 - 512x512 the amount of time it takes is worth the quality, if you drop below 480x480 it starts to get a bit shoddy.
The 512x640 jump is not worth the extra time to run in my opinion.
Overall quality workflow!
Below timings on how long each resolution took.
Default Setup -
(512 x 640, 101 length) 784.79 seconds First Run
(512 x 640, 101 length) 555.50 seconds Second Run
(512 x 640, 101 length) 577.36 seconds Third Run
Default Setup - Reduced Resolution 512 x 512
(512 x 512, 101 length) 337.76 seconds First Run
(512 x 512, 101 length) 274.98 seconds Second Run
(512 x 512, 101 length) 250.95 seconds Third Run
Default Setup - Reduced Resolution 480 x 480
(480 x 480, 101 length) 197.73 seconds First Run
(480 x 480, 101 length) 196.85 seconds Second Run
(480 x 480, 101 length) 196.12 seconds Thirds Run
Default Setup - Reduced Resolution 416 x 416
(416 x 416, 101 length) 135.02 seconds First Run
(416 x 416, 101 length) 135.92 seconds Second Run
(416 x 416, 101 length) 134.86 seconds Thirds Run
You are sure you're not running in CPU mode? (looking at the times...thats insane.). It should work better at any resolution. the only thing going on here is skipping the step of decoding/encoding, which takes forever...
Hmm, upon considering. 16g memory card. naa, still seems far too long. if my 512x512 took 100 seconds, yours should be like maybe 1/3rd longer if things scale like that. You should be getting 130ish times. Something is off.
Thought a bit more (trying to snort coffee to wake brain up.) alright, so I suspect the workflow you might be comparing to might do a descaling process before it runs through the pipeline. This of course will make things go blazing fast. Something I considered doing and simply tell people to use larger sizes, then upscale it post refiner steps. I chose not to on this workflow because people can do that themselves (lots of people simply hate downscale/upscale. I don't mind, but best to leave out then pop in.)
So, when you go in raw and large, your GPU might get used up and hit a bottleneck. once your GPU hits that like 97% used mark, it tends to get locked and takes forever. this might be whats going on with you.
What I would do is downscale step before refiner. like, right out of the gate, then add a step after refiner to upscale back. You will lose some quality, but you will have videos before next christmas.
@saturngfx Yeah running in GPU mode, This was not a comparison take, this was just ran against yours, I was more than happy with the speed, I have tried pretty much most workflows that has come out, this I think gives me quality results for the time taken, I dont mind the waiting part as i usually run these whilst working X-D.
I will look into your recommendations as I am trying to improve my ability on this! But I will be upgrading and getting a new pc soon so I wont have to worry about VRAM etc.
--To confirm my gpu and ram are maxing out with the setting and that is likely the reason why its dragging on hence the massive speed increase when I drop the resolution--
@Aicush Thanks for the update. btw, image 2 video version 4 just dropped using this...if you use that then that should increase your speed there also. just...be warned. Flux is a beast.
@saturngfx Legend thanks so much for letting me know :-) Ill give this a go tomorrow morning and report my findings, seriously thanks for the awesome workflows!!
I'm getting strange checkerboard artifacts on my videos, any idea why? it's like squares with blurred edges, thought it was the VA Decode (Tiled) but when previewing the output before the VAE decodes they still have the same issue
Hmm, straight out of the box or can you remember the things you altered?
@saturngfx Out of the box I believe, I'll give it another whirl, would you mind sharing models you used specifically?
@Lebofly fast model and the fastlora (at negatives). really thats it. you can add other loras of course and you can use any of the hunyuanvideo models.
How is the LORA, with diffusion pipe or other? formed, what are the necessary PC capacities?
Lora? what LoRA? the fastvideo LoRA?
When using the Fastvideo lora, if using the fast model, ensure it is a negative value. -0.3 or -0.4. otherwise keep it positive. if you use other loras, you can turn it down, but it helps speed up steps and gives more detail in general...resolves the weird blotchy blocky mess.
As far as PC capacities? I assume you mean can it run on XYZ type question. I dont know...if you can run regular hunyuan video, you can do it here also. the only secret sauce is no steps inbetween the video process and the refinement process. no decoding just to encode again...otherwise, there really isn't anything special, just bypassing some unnecessary very long steps of unloading and reloading models. Also because it hits a refiner twice, you need less initial steps because the refiners work on the previous picture to fix issues, so...yeah, less steps, faster because no decode/encode...thats it really. everything else is vanilla hunyuan video.
@saturngfx I mean how he trained the "Final V3! DeJanked Speed Hack Hunyuan T2V Final Boss", with diffussion-pipe?
@saturngfx I mean, how do you train your LORA, Whit diffusion-pipe?
@OFIA I think you might be commenting in the wrong area. this isn't a LoRA, its just a workflow. I didn't train any loras, just slapped nodes together.
Amazing comfy kung fu! Thank you!