
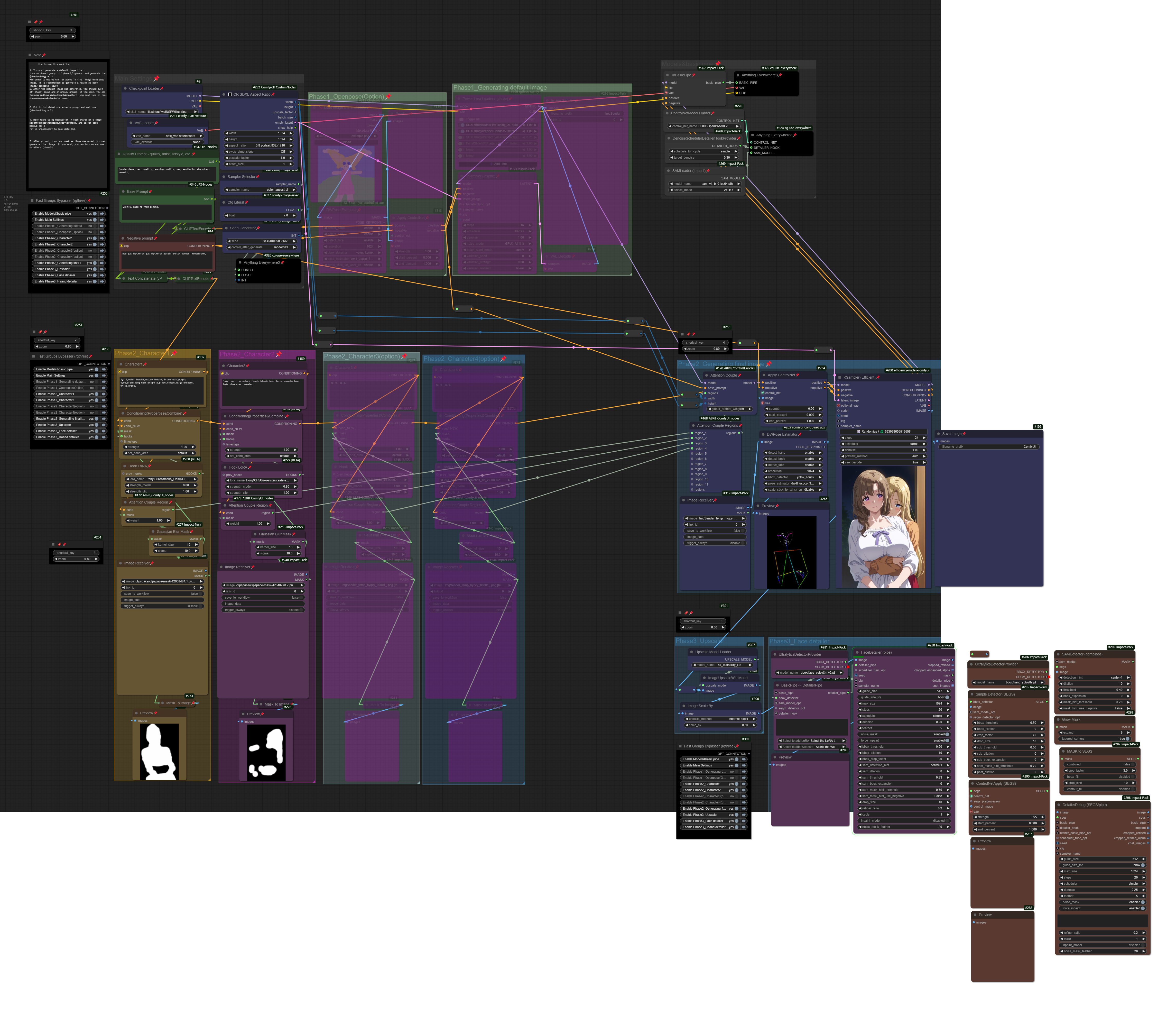


How to use : HERE
This workflow may require a relatively large amount of VRAM.
v2.0 - Image Sender nodes have been replaced with Load Image nodes.
Each character’s Detailer has been modified to work based on that character’s mask.
The conditioning has been connected so that it is input separately for each character.
v1.5 - Organized nodes, replaced the DWPose Estimator in Phase 2 with OpenPose Pose. A realistic base image is no longer required.
This workflow utilizes the Attention Couple node for regional conditioning.
It operates in two phases to generate images.
While I understand that not working in a single queue might not be ideal, this is an attempt to achieve better results.
If you have any ideas for improvements to this workflow, please let me know.
This workflow was inspired by : https://civarchive.com/models/541881/regional-conditioning-with-lora-support
The Attention Couple node was implemented using A8R8's node. : https://github.com/ramyma/A8R8_ComfyUI_nodes
Description
FAQ
Comments (14)
Thank you SO much for making this workflow! <3
it's one of the few that don't give me an error for not found nodes :"3
Hi, which version of python are u running in the enviroment? 3.12 is not compatible with YoloWorld-Sam node, and I´m not able to update the comfyUI to 3.13
@jakomz1560 I'm using python 3.10! also I feel like I should mention this but I'm actually using a ZLUDA fork of ComfyUI since I have an AMD GPU (I'm saying this since idk if it's important info...)
@CappyAdams Hello! I saw your message on this workflow interface. Have you successfully created a character containing multiple loras through this workflow? If you have time, can I ask for your advice? I am unable to run this workflow properly, but I really want to create an image containing multiple Lora characters. Thank you!
hello friends I get this error: CLIPTextEncode
CLIPTextEncode.encode() missing 1 required positional argument: 'clip'
Have you bypassed Models&Basic pipe group? It must be turn on. also Main settings group too.
Another suggestion is that the connection for the clip output from the Power LoRA Loader node seems to be disconnected. It should be connected to the Anything Everywhere3 node. If you have made any modifications to the workflow, please compare it with the workflow I uploaded to verify the changes.
@Likke0703 thanks!!!!!!!
hey, thanks a lot for this amazing workflow. only workflow that i found to be working :").
However I am facing trouble with pose estimator. as the checkpoint which i'm using is focused on anime style images. Is there a workaround for this?
Also how can I use an existing image rather than generating a base image.
1. I have used a realistic style checkpoint in Phase 1. The quality doesn't matter as long as the OpenPose processor can recognize it. In Phase 2, I switch to a different checkpoint.
Although it would have been possible to improve convenience by using nodes like a switch, I chose not to include them due to concerns about making the workflow overly complex. However, if there are requests for such a feature, I will consider adding a version of the workflow with this functionality.
2. If you want to work with an existing image, connect an image loader node to the input of the 'Image Sender' node in the 'Phase1_Generating default image' node group and run it once. This will transfer the image to the 'Image Receiver' nodes placed in Phase 2.
I recommend bypassing the 'Generating default image' group and using only the 'Image Sender' separately for this purpose.
Keep in mind that the OpenPose processor may struggle to recognize animated style images effectively in this case as well.
@Likke0703 Thanks. I'm a little new to ComfyUI, so glad for detailed your explanation.
I replaced the DWPose Estimator with OpenPose Pose and that seems to be working for anime images as well saving me the hassle of using different checkpoint.
I also tried using combine hooks to put more LORAs in phase 2. I this a recommended way or is there are better way for this?
@pf01 Yes, you can use more hook LORAs if you want to.
@pf01 Thank you for the advice! With so many nodes in ComfyUI, it's always great to learn about better options. I can upload a modified workflow incorporating people's advice.