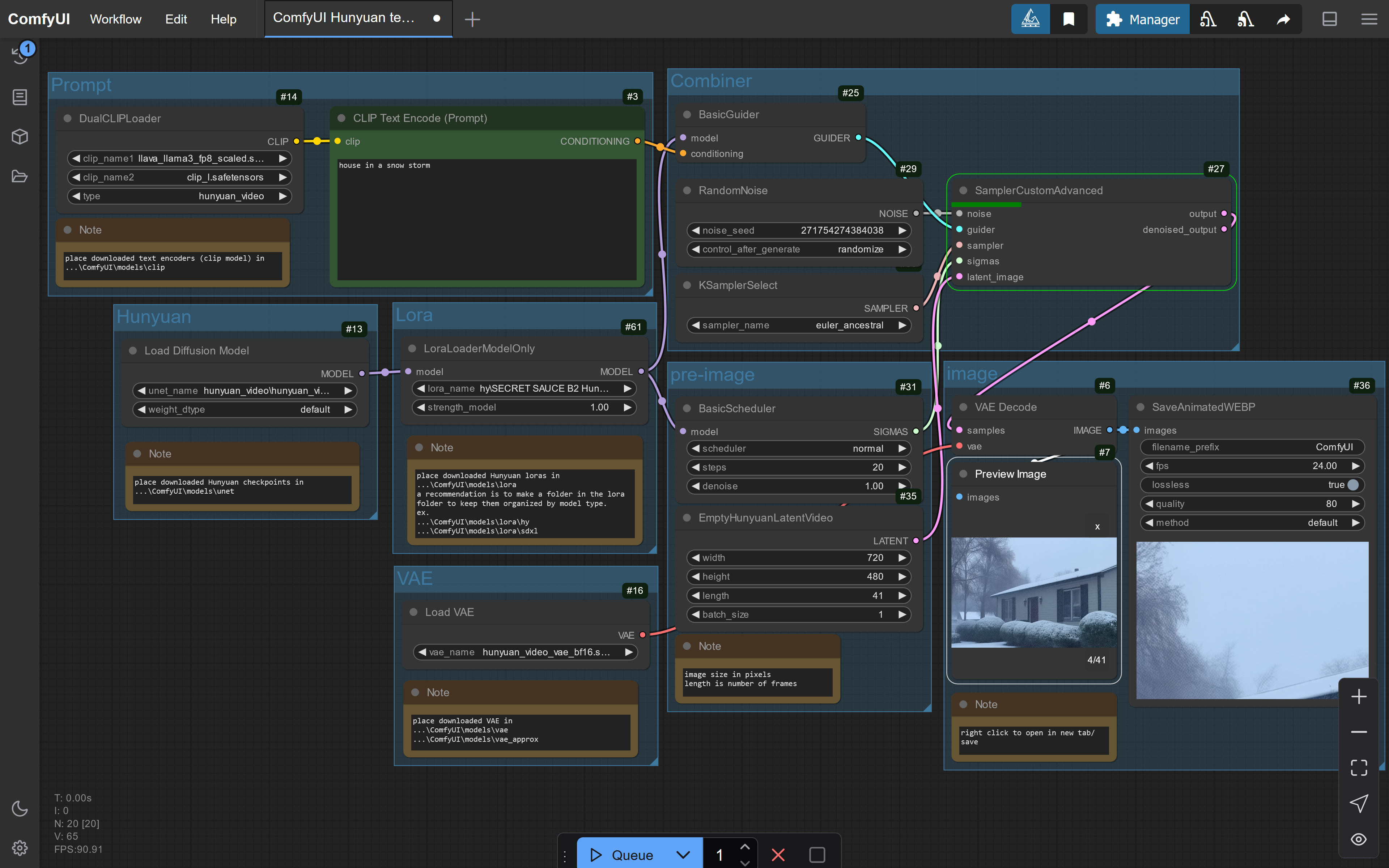



Text to video using Hunyuan checkpoint.
32GB ram and 16GB vram/ laptop 3080TI.
You can find Necessary downloads here
https://comfyanonymous.github.io/ComfyUI_examples/hunyuan_video/
Description
added lora node
FAQ
Comments (37)
Is there a reason to use any of the workflows here on civitai over the Kijai one ? i see u can choose the sampler like euler and stuff here.I got a RTX 4090 dunno if that matters.
This workflow uses nodes found in comfyUI. No custom nodes. The one made by Kijai require you to download the custom nodes. Not a hard thing to do, just that this one has less steps to get up and running. I choose the euler sampler because that was the default.
@gblue Ah ok ,thanks for clarifying this for me.
can you please make img2video
have you seen the ip2v , thats the only image2video we have for hunyuan, but i dont think its far.
What about Guidance and Shift though? They're quite important with this model.
I have tried the flux guidance node and sd3 shift node, but did not see much better quality from the results. They may offer more control if you are looking for something exact.
I seen that case happening for others so i need to add that when installing hunyuan through comfy in clip folder there is no llama file, i had to manually download and put it there. My other workflow didnt needed that but here due to double clip loader its necessary. Idk why but it drains much less vram. I was using lora and i reduced the FPS to 12 and frames to 53 to make it 4-5 sec clip. And process was taking only 17gb of vram and processing was much faster than with my other workflow. Thank you for taking the time to make this one.
Why is that? I showed it at the gallery
OK, changing FP8 to BF16 will work, why ?, can you do an FP8 workflow
The workflow you used was not the one i uploaded, but it should have still worked. The Flux Guidance node and sd3 node are in the workflow you used. This workflow works with both FP8 and BF16. Maybe try to redownload the FP8 video model.
Hi there...do you know how to train a Hunyuan Lora? thanks
@gblue Thanks man, appreciate!
I keep getting noise (rainbow pixels) when using fp6 model and i get a OOM using fp16 model (RTX 3090). Any tips ?
i have not had those issues. i would try to update comfyui and make sure that dual clip is set to hunyuan video. i use a 3080ti.
gives me out of memory error :/ using a 4070 ti super 16gb vram
I have this running at 400 x 640 61 frames, 480 x 720 41 frames. Try smaller size or less frames.
@gblue so that kind of worked, it generates until VAE Decode but then the same thing happens..
@TheQuacktastic try replacing VAE Decode node with VAE Decode (Tiled) with settings 128, 64, 64, 8.
@gblue that did it :) thanks for the assistance
Hi there! I cant locate my hunyuan video model in the diffusion model loader. I placed it as it was said, in Unet folder, but i cant see it on my comfyUI. I'm using forge btw
I started with the vanilla comfy ui (v3.10) and under the Model Library on the LHS along the top you have to click Load all Folders and then you should be able to click the arrows to select different diffusion models. For vanilla comfy ui everything has to be safetensors.
@Webtester70711 doesnt work for me. The Unet loader node does not see anything but .gguf files. Hunyuan is .safetensors. I just renamed it to .gguf and it sees it! Of course this won't work, so i need another solution. Cant find it on the web :(
@alex2004ru1116 Theres a Unet loader that can load safetensors! it looks almost identical
@ARCFX can you share a link on this loader?
so I got very good results using a different set of files (not including all of the links here but listing all files I used) :https://huggingface.co/openai/clip-vit-large-patch14/tree/main
openai/clip-vit-large-patch14
downloaded 'model.safetensors' (1.71GB) and renamed as 'clip_l_vit_large_patch14.safetensors'
clips:
clip_l_vit_large_patch14.safetensors
llava_llama3_fp8_scaled.safetensors
loras:
SECRET SAUCE B3 Hunyuan.safetensors
https://huggingface.co/Kijai/HunyuanVideo_comfy/tree/main
unet:
hunyuan_video_FastVideo_720_fp8_e4m3fn.safetensors
vae:
hunyuan_video_vae_fp32.safetensors
I'm using same files but the node SamplerCustomAdvanced seems stuck... 0/20 :(
Using a 4070 SUPER with 16Go VRAM
how can i use more than 1 lora like 1 lora for character and 1 lora for pose/movement?
copy and paste the model only lora and connect it between the diffusion model and lora model
how can i add missing nodes? (i use comfyui on runpod)
comfy ui manager
I'm getting nothing by rainbow static. My vae decode tiling is:
128
64
64
8
The only thing I might be doing wrong is that i'm using t5 and clip_l instead of llama and clip_l. But I feel like that shouldn't make a difference? Right?
You should definitely use llava_llama3_fp8 and clip_l.
Thanks for sharing.
It's a great workflow, very clean and explained. It didn't work for me, I think it's a problem with my hardware.